最近一例在11.2.0.4 2NODES RAC on linux7 增加节点时不是很顺利,此版本是ORACLE的认证版本但是还是兼容性还不是那么顺滑,9年前分享过在linux6上addnode还相对顺利《Oracle 11g R2 RAC addnode (增加RAC节点) 实践和注意事项》。 遇到的问题也较多涉及IB,网络,bug, 损坏,补丁等,简单记录。
1, IB心跳网不通
addnode前需要检查现存节点是否正常,发现node2心跳不通,使用的是IB全家桶, 进看IB状态
[oracle@anbob001:/home/oracle]$ethtool ib0
Settings for ib0:
Supported ports: [ ]
Supported link modes: Not reported
Supported pause frame use: No
Supports auto-negotiation: No
Supported FEC modes: Not reported
Advertised link modes: Not reported
Advertised pause frame use: No
Advertised auto-negotiation: No
Advertised FEC modes: Not reported
Speed: 56000Mb/s
Duplex: Full
Port: Other
PHYAD: 255
Transceiver: internal
Auto-negotiation: off
Cannot get wake-on-lan settings: Operation not permitted
Link detected: yes
Dec 13 23:34:42 anbob002 kernel: ib1: transmit timeout: latency 1002653 msecs
Dec 13 23:34:42 anbob002 kernel: ib1: queue (5) stopped, tx_head 2318340524, tx_tail 2318340429
Dec 13 23:34:52 anbob002 kernel: ib1: transmit timeout: latency 1012637 msecs
Dec 13 23:34:52 anbob002 kernel: ib1: queue (5) stopped, tx_head 2318340524, tx_tail 2318340429
Dec 13 23:35:02 anbob002 python: File "/opt/zdata/compute/python/lib/python2.7/logging/handlers.py", line 117, in __init__
Dec 13 23:35:02 anbob002 python: File "/opt/zdata/compute/python/lib/python2.7/logging/handlers.py", line 64, in __init__
Dec 13 23:35:02 anbob002 python: File "/opt/zdata/compute/python/lib/python2.7/logging/__init__.py", line 913, in __init__
Dec 13 23:35:02 anbob002 python: File "/opt/zdata/compute/python/lib/python2.7/logging/__init__.py", line 943, in _open
Dec 13 23:35:02 anbob002 kernel: ib1: transmit timeout: latency 1022653 msecs
Dec 13 23:35:02 anbob002 kernel: ib1: queue (5) stopped, tx_head 2318340524, tx_tail 2318340429
Dec 13 23:35:12 anbob002 kernel: ib1: transmit timeout: latency 1032669 msecs
Dec 13 23:35:12 anbob002 kernel: ib1: queue (5) stopped, tx_head 2318340524, tx_tail 2318340429
Dec 13 23:35:22 anbob002 kernel: ib1: transmit timeout: latency 1042653 msecs
该问题为IB驱动BUG, IB堵塞,暂时可以通过REBOOT解决。
2, addnode 耗时久、流量小
addnode会传送执行节点的文件scp到新节点,对于trace logfile较多如adump,几十万的trace小文件传递, 目标root.sh时同样还要对这些文件授权,很有可能浪费几个小时。
解决在增加节点前清理trace文件。
3, addnode 失败 with PRCF-2015 PRCF-2002
addnode中间连接断开,多次尝试相同现象,心跳网虽是IB,但这个环境的public network是1000M电口, 但理论也不应该存在瓶颈,addnode使用的是public network.
Instantiation of add node scripts complete Copying to remote nodes (Tuesday, April 27, 2021 3:28:31 PM CST) .............................................................................................. .WARNING:Error while copying directory /u01/app/11.2.0/grid with exclude file list '/tmp/OraInstall2021-04-27_03-28-20PM/installExcludeFile.lst' to nodes 'anbob003'. [PRKC-PRCF-2015 : One or more commands were not executed successfully on one or more nodes : ] ---------------------------------------------------------------------------------- anbob003: PRCF-2002 : Connection to node "anbob003" is lost ---------------------------------------------------------------------------------- Refer to '/u01/app/oraInventory/logs/addNodeActions2021-04-27_03-28-20PM.log' for details. You may fix the errors on the required remote nodes. Refer to the install guide for error recovery. 96% Done.
在文件传输时ping远程节点达40ms时延,网络不是很好。文件传速理论并不是firewall kill的idle connect, Oracle存在一个bug较匹配,因为使用scp服务,默认SSH服务的最大并发不足,oracle建议调整加大ssh server端maxstartups ,MaxStartups 默认是10:30:60 “start:rate:full”,表示最大并发10个,如果超过后会有rate 30/100% 可能性失败,如果超过 full 60时会肯定失败,但是只是限制未认证的连接, 需要重启sshd服务。 建议加大到40,但是重试还是失败,继续加大到100, 100:30:100 后重试还是失败, 问题还是网络太差导致。
4, 网络差
这样的网络就可能会导致数据包发送失败,涉及网络包失败重传优化问题,RFC2018提供了一个SACK的方法,与报文的确认机制相关,SACK(Selective Acknowledgment),SACK是一个TCP的选项,来允许TCP单独确认非连续的片段,用于告知真正丢失的包,只重传丢失的片段。当前是禁用的,下面尝试启用SACK
sysctl -w net.ipv4.tcp_sack=1
再次尝试addnode ,成功解决。
tcp_sack 不是个万能药,如果你注意EXADATA中的配置,最值实践还是禁用SACK的,并且在OEL UEK4中同样存在启用TCP_SACK后性能变差。 遇到问题时建议测试一下,事实胜于雄辩。
5, HAS 无法启动
这是11G 在LINUX7上的著名的问题,因为有init.d改为systemd,ohasd服务需要在root.sh前安装补丁,或手动创建servcie,眼快手极的手动启服务。直到看到init.ohasd run进程。补丁安装18370031也可以。
注意root.sh 如果失败了,从11.2.0.2开始是可以重复的跑的继续安装。
6, crs-10131 /var/tmp/.oracle/npohasd mkfifo: cannot create fifo ‘/var/tmp/.oracle/npohasd’: file exists
如果没有看到 /etc/init.d/init.ohasd run这样的进程,说明ohasd服务都没启 看日志文件提示
crs-10131 /var/tmp/.oracle/npohasd mkfifo: cannot create fifo '/var/tmp/.oracle/npohasd': file exists
是因为之前网络传失败时/var/tmp/.oracle/npohasd文件传送了过来,文件的生成时间早于进程启动时间, 建议删除。
7, PROCL-26 OLR initalization failured, rc=26
再次尝试root.sh,又失败了
2021-04-27 23:01:46.275: [ OCROSD][1228334000]utread:3: Problem reading buffer 1907f000 buflen 4096 retval 0 phy_offset 102400 retry 5 2021-04-27 23:01:46.275: [ OCRRAW][1228334000]propriogid:1_1: Failed to read the whole bootblock. Assumes invalid format. 2021-04-27 23:01:46.275: [ OCRRAW][1228334000]proprioini: all disks are not OCR/OLR formatted 2021-04-27 23:01:46.275: [ OCRRAW][1228334000]proprinit: Could not open raw device 2021-04-27 23:01:46.275: [ OCRAPI][1228334000]a_init:16!: Backend init unsuccessful : [26] 2021-04-27 23:01:46.276: [ CRSOCR][1228334000] OCR context init failure. Error: PROCL-26: Error while accessing the physical storage 2021-04-27 23:01:46.276: [ default][1228334000] OLR initalization failured, rc=26 2021-04-27 23:01:46.276: [ default][1228334000]Created alert : (:OHAS00106:) : Failed to initialize Oracle Local Registry 2021-04-27 23:01:46.277: [ default][1228334000][PANIC] OHASD exiting; Could not init OLR
这原因是因为OLR损坏了, root.sh会修复,
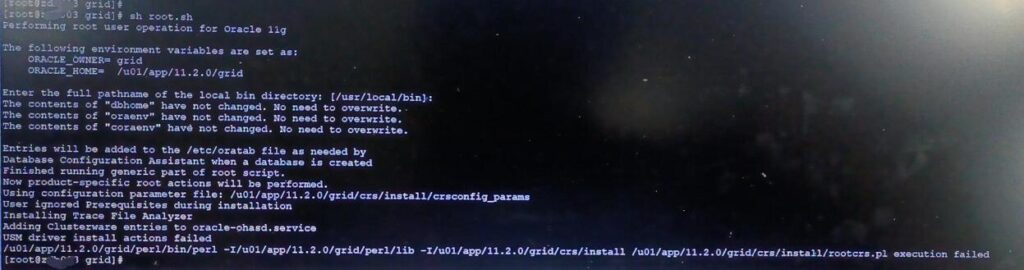
Root.sh Failed USM Driver Install Actions Failed On Second Node ( ACFS-11022 ) (Doc ID 1477313.1) 之前RAC是安装过17475946 patch的。
这环境看来有点糟糕, 清理了,重新来addnode, root.sh
8,node1 addnoe 会提示node3已存在,需要清理一下。
#as root
$GRID_HOME/bin/crsctl delete node -n anbob003
# as grid
./runInstaller -updateNodeList ORACLE_HOME=CRS_home "CLUSTER_NODES={remaining_nodes_list}" CRS=TRUE
解决了addnode
node3再次root.sh时又失败,提示
crs-4046 invalid coracle clusterware configuration crs-4000 command create failed, or completed with errors
解决这个问题执行:
# /crs/install/rootcrs.pl -deconfig -force -verbose
9, ACFS-9459 错误
但是deconfig又报如下错误
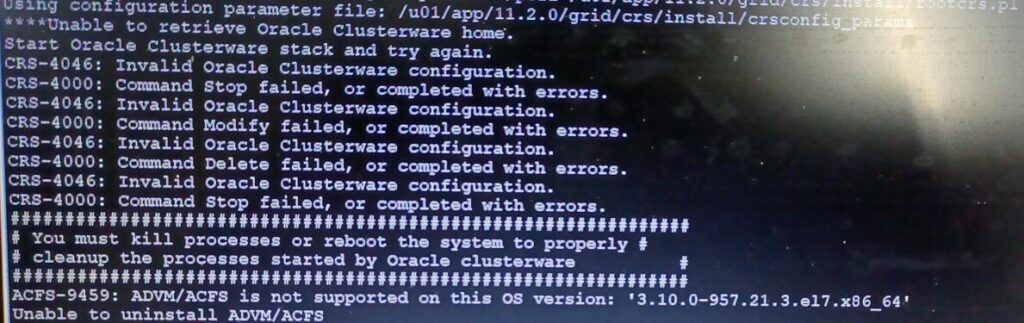
ps -ef|grpe u01
并没有ORACLE_HOME下的活动进程,我认为主要是解决ACFS-9459 错误, 不支持当前的操作系统内核,相关的bug 还有21233961.
cd /u01/app/grid/11.2.0/install/usm/Novell/SLES11/x86_64 mv 3.0.61-0.9 3.0.61-0.9_bak ln -s 3.0.13-0.27 3.10.0-957.21
这种link版本的方式无法解决,后来回滚了node3 上的ACFS补丁, deconfig成功, 同时root.sh也顺利完成。 判断应该是oracle bug,在安装顺序上ACFS补丁有冲突。
10, OUI 提示Error in invoking target ‘install’ of makefile ‘/u01/app/oracle/product/11.2.0/dbhome_1/sysman/lib/ins_emagent.mk’.
OUI软件安装是提示
Error in invoking target ‘install’ of makefile ‘/u01/app/oracle/product/11.2.0/dbhome_1/sysman/lib/ins_emagent.mk’
$ORACLE_HOME/install/make.log 日志显示
collect2: error: ld returned 1 exit status /u01/app/oracle/product/11.2.0/dbhome_1/sysman/lib/ins_emagent.mk:176: recipe for target '/u01/app/oracle/product/11.2.0/dbhome_1/sysman/lib/emdctl' failed make[1]: Leaving directory '/u01/app/oracle/product/11.2.0/dbhome_1/sysman/lib' /u01/app/oracle/product/11.2.0/dbhome_1/sysman/lib/ins_emagent.mk:52: recipe for target 'emdctl' failed make[1]: *** [/u01/app/oracle/product/11.2.0/dbhome_1/sysman/lib/emdctl] Error 1 make: *** [emdctl] Error 2
原因
“ins_emagent.mk”上的链接错误
解决方法:
不用关闭OUI,另打开一个窗口编辑$ORACLE_HOME/sysman/lib/ins_emagent.mk
把
$(MK_EMAGENT_NMECTL)
替换为
$(MK_EMAGENT_NMECTL) -lnnz11
OUI点击重试。
11, 第一个节点执行root.sh 失败报
/u01/grid/bin/srvctl start nodeapps -n krish1 … failed
FirstNode configuration failed at /u01/grid/crs/install/crsconfig_lib.pm line 9379.
/u01/grid/perl/bin/perl -I/u01/grid/perl/lib -I/u01/grid/crs/install /u01/grid/crs/install/rootcrs.pl execution failed
$ /u01/grid/root.sh CRS-4256: Updating the profile CRS-4266: Voting file(s) successfully replaced ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 6845b39c31064fc8bfa54c7bbaea4ffd (/dev/oracleasm/disks/VOL1) [DATA] Located 1 voting disk(s). CRS-2672: Attempting to start 'ora.asm' on 'krish1' CRS-2676: Start of 'ora.asm' on 'krish1' succeeded CRS-2672: Attempting to start 'ora.DATA.dg' on 'anbob1' CRS-2676: Start of 'ora.DATA.dg' on 'anbob1' succeeded /u01/grid/bin/srvctl start nodeapps -n anbob1 ... failed FirstNode configuration failed at /u01/grid/crs/install/crsconfig_lib.pm line 9379. /u01/grid/perl/bin/perl -I/u01/grid/perl/lib -I/u01/grid/crs/install /u01/grid/crs/install/rootcrs.pl execution failed $srvctl start nodeapps -n abctest1 PRCR-1013: Failed to start resource ora.ons PRCR-1064: Failed to start resource ora.ons on node abctest1 CRS-5016: Process "/u01/app/product/11.2.0/crs/opmn/bin/onsctli" spawned by agent "/u01/app/product/11.2.0/crs/bin/oraagent.bin" for action "start" failed: details at "(: CLSN00010 :)" in "/u01/app/product/11.2.0/crs/log/abctest1/agent/crsd/oraagent_grid/oraagent_grid.log" CRS-2674: Start of 'ora.ons' on 'anbob1' failed $ vi $ORACLE_HOME/cfgtoollogs/crsconfig/rootcrs_$HOSTNAME.log 2015-01-26 15:26:11: nodes_to_start= 2015-01-26 15:26:32: exit value of start nodeapps/vip is 1 2015-01-26 15:26:32: output for start nodeapps is PRCR-1013 : Failed to start resource ora.ons PRCR-1064 : Failed to start resource ora.ons on node Node1 CRS-5016: Process "/u01/app/11.2.0.4/grid/opmn/bin/onsctli" spawned by agent "//bin/oraagent.bin" for action "start" failed: details at "(:CLSN00010:)" in "//log/anbob1/agent/crsd/oraagent_oracle/oraagent_oracle.log" CRS-2674: Start of 'ora.ons' on 'anbob1' failed 2015-01-26 15:26:32: output of startnodeapp after removing already started mesgs is PRCR-1013 : Failed to start resource ora.ons PRCR-1064 : Failed to start resource ora.ons on node anbob1 CRS-5016: Process "//opmn/bin/onsctli" spawned by agent "//bin/oraagent.bin" for action "start" failed: details at "(:CLSN00010:)" in "//log/anbob1/agent/crsd/oraagent_oracle/oraagent_oracle.log" CRS-2674: Start of 'ora.ons' on 'anbob1' failed 2015-01-26 15:26:32: //bin/srvctl start nodeapps -n anbob1 ... failed 2015-01-26 15:26:32: Running as user oracle: //bin/cluutil -ckpt -oraclebase /u01/app/oracle -writeckpt -name ROOTCRS_NODECONFIG -state FAIL 2015-01-26 15:26:32: s_run_as_user2: Running /bin/su oracle -c ' //bin/cluutil -ckpt -oraclebase /u01/app/oracle -writeckpt -name ROOTCRS_NODECONFIG -state FAIL ' 2015-01-26 15:26:33: Removing file /tmp/fileoy7dDY 2015-01-26 15:26:33: Successfully removed file: /tmp/fileoy7dDY 2015-01-26 15:26:33: /bin/su successfully executed $ vi $GRID_HOME/opmn/logs/ons.log * [2015-08-26T15: 37: 02 + 08: 00] [internal] getaddrinfo (:: 0, 6200, 1) failed (Hostname and service name not provided or found): Connection timed out -- or -- [2015-01-26T15:26:15+04:00] [ons] [NOTIFICATION:1] [104] [ons-internal] ONS server initiated [2015-01-26T15:26:15+04:00] [ons] [ERROR:1] [17] [ons-listener] 172.0.0.1,6100: BIND (Cannot assign requested address)
If the above error message exists, the reason is / etc / hosts file corresponding IP address is not localhost 127.0.0.1. Workaround is to ensure that as DNS and / etc / hosts file is set up correctly localhost, DNS or / etc / hosts file depends on (/etc/nsswitch.conf, or /etc/netsvc.conf depend on platform), these profiles setting naming solutions, refer to the MOS ID 942166.1 or ID 969254.1 documents for processing.
[2015-08-26T15: 39: 42 + 08: 00] [ons] [NOTIFICATION: 1] [104] [ons-internal] ONS server initiated [2015-08-26T15: 39: 42 + 08: 00] [ons] [ERROR: 1] [17] [ons-listener] any: BIND (Address already in use) [2015-08-26T15: 48: 40 + 08: 00] [ons] [NOTIFICATION: 1] [104] [ons-internal] ONS server initiated [2015-08-26T15: 48: 40 + 08: 00] [ons] [ERROR: 1] [17] [ons-listener] any: BIND (Address already in use)
The reason is that there are other processes occupied ONS port services
[Grid @ abctest1 logs] $ grep port $ ORACLE_HOME / opmn / conf / ons.config localport = 6100 # line added by Agent remoteport = 6200 # line added by Agent [Root @ abctest1 /] # lsof | grep 6200 | grep LISTEN ons 16413 grid 6u IPv6 162533 TCP *: 6200 (LISTEN)
Ons you can see the process of taking up the process ID16413 port 6200, the solution is to ensure that the port is not occupied by other conduct, if it is occupied before performing rootupgrade.sh script to upgrade, it may be because older versions of the process ons still running.
[Grid @ abctest1 oraagent_grid] $ cd $ ORACLE_HOME / opmn / logs / [Grid @ abctest1 logs] $ ls -lrt total 8 -rw-r - r-- 1 grid oinstall 576 Aug 26 15:48 ons.log.abctest1 -rw-r - r-- 1 grid oinstall 267 Aug 26 15:48 ons.out [Grid @ abctest1 logs] $ cat ons.log.abctest1 [2015-08-26T15: 48: 40 + 08: 00] [ons] [NOTIFICATION: 1] [104] [ons-internal] ONS server initiated [2015-08-26T15: 48: 40 + 08: 00] [ons] [ERROR: 1] [17] [ons-listener] 0000: 0000: 0000: 0000: 0000: 0000: 0000: 0001,6100: BIND (Can not assign requested address)
This may be partially configured IPV6, 11gR2 Grid Infrastructure does not support IPv6. The solution is provided at $ GRID_HOME / opmn / conf / ons.config and ons.config file the following parameters:
interface = ipv4
Here is the first error occurred two kinds, ons process ID16413 process takes up 6200 port, the solution is to ensure that the port is not occupied by other conduct
[Root @ abctest1 /] # lsof | grep 6200 | grep LISTEN ons 16413 grid 6u IPv6 162533 TCP *: 6200 (LISTEN) [Root @ abctest1 /] # kill -9 16413
And then re-execute the root.sh script
[Root @ abctest1 /] # ./u01/app/product/11.2.0/crs/root.sh
Performing root user operation for Oracle 11g
The following environment variables are set as:
ORACLE_OWNER = grid
ORACLE_HOME = /u01/app/product/11.2.0/crs
Enter the full pathname of the local bin directory: [/ usr / local / bin]:
The contents of "dbhome" have not changed. No need to overwrite.
The contents of "oraenv" have not changed. No need to overwrite.
The contents of "coraenv" have not changed. No need to overwrite.
Entries will be added to the / etc / oratab file as needed by
Database Configuration Assistant when a database is created
Finished running generic part of root script.
Now product-specific root actions will be performed.
Using configuration parameter file: /u01/app/product/11.2.0/crs/crs/install/crsconfig_params
User ignored Prerequisites during installation
Installing Trace File Analyzer
PRKO-2190: VIP exists for node abctest1, VIP name abctest1-vip
Preparing packages for installation ...
cvuqdisk-1.0.9-1
Configure Oracle Grid Infrastructure for a Cluster ... succeeded
After the occupation kill off process 6200 port, root.sh script can be executed successfully.
12, crsctl stop crs后,再手动crsctl start crs启动失败
GI ALERT LOG
2021-12-27 16:19:56.087:
[ohasd(59057)]CRS-8017:location: /etc/oracle/lastgasp has 2 reboot advisory log files, 0 were announced and 0 errors occurred
2021-12-27 16:19:56.396:
[ohasd(18718)]CRS-0704:Oracle High Availability Service aborted due to Oracle Local Registry error
[PROCL-24: Error in the messaging layer Messaging error [gipcretAddressInUse] [20]].
Details at (:OHAS00106:) in /u01/app/11.2.0/grid/log/saledb1/ohasd/ohasd.log.
分析
ps -ef | grep ohasd
如果看到2条sh /etc/init.d/init.ohasd run 记录
kill 其中一个就可以正常启动了,这通常发生在11.2.0.4 安装时因为systemd启动方式,上面#5问题提到过,手动创建的service, 同时后期的PSU又包含了one-off patch,会导致 启动重复。
解决
清理掉之前手动增加的服务
systemctl stop ohas.service
systemctl disable ohas.service
rm -f /usr/lib/systemd/system/ohas.service
保留oracle PSU创建的ohasd服务即可。/etc/systemd/system/oracle-ohasd.service
13, root.sh时失败注意分析是不是LINUX 最小化安装,缺失了oracle要求的RPM.
14, root.sh 失败,oc4j启动失败,因为多次重装,原孤儿文件没有清理,案例<root.sh failed with OC4J start failed when install oracle 11g RAC on Linux 7>