PostgreSQL 32位的事务ID,是个比较头疼的问题,如果事务ID耗尽回卷时,回影响数据库的可用行,近期一客户的postgresql数据库出现了事务回卷问题,导致所有业务无法执行, 早期可能日志中会有提示,后期数据库进入只读模式,需要人工干预,同时日志提示下面的错误:
2025-05-16 08:43:38.265 [74098] WARNING: database "postgres" must be vacuumed within 1000000 transactions
2025-05-16 08:43:38.265 HINT: To avoid a database shutdown, execute a database-wide VACUUM in that database.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.
2025-05-16 08:43:48.640 [5764] ERROR: database is not accepting commands to avoid wraparound data loss in database "postgres" (10182)
2025-05-16 08:43:48.640 [5764] HINT: Stop the postmaster and vacuum that database in single-user mode.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.
事务 ID 回卷
在 PostgreSQL 的数据库中,更新的每一行都会从事务控制系统获得一个事务 ID。这些 ID 实现了向其他活动事务显示哪些行,主要用于 MVCC(多版本并发控制)和事务可见性判断。PostgreSQL 中的事务 ID 就是 32 位的整数数据类型,长度 4字节,表示范围是 [0 , 4294967295] 。采用循环(modulo 2^32 )方式管理,单调递增。当到达最大值(2^32-1) 后又开始从 3 开始使用(将 0、1、2 保留给系统用)。这种现象一般称为事务 ID 回卷(Wraparound)。只有大约四十亿(2^32)个可能的事务 ID(一个新事务,最多有 2^31 个事务比它早,最多有 2^31 个事务比它晚),(像OpenGauss中已改为8字节64位,该问题几乎不会出现),但是对于PostgreSQL写入密集型工作负载非常高的数据库系统,40 亿个事务可以在几周内用完。因此需要监控 wraparound(事务 ID 回卷)风险。如果存在 2^31(约20亿) 个未清理的事务,PostgreSQL 将阻止进行写入操作,并将数据库切换到只读模式。
以下任何一个或多个条件,都可能导致事务 ID 回卷的问题。
- Autovacuum 设置为关闭(当然并不能完全关闭)
- 长时间运行的事务。
- 繁重的 DML 操作,迫使取消自动清理工作进程。
- 大量会话或连接长时间保持锁定。
- 不当的prepared transaction 未结束
- 过多的子事务隐式地增加了 XID .
- 过期的事务槽
事务 ID 会存储在数据页中。PG还有个虚拟的事务 ID,由会话的 pid 和 本地事务 ID(会话内部唯一),这个本地事务 ID 不会回卷。前面那个事务 ID 也叫全局事务 ID 。
# select locktype, database,transactionid,virtualtransaction,pid,mode,granted
from pg_locks where transactionid <> '' ;
PostgreSQL 在技术上能够很好地处理事务 ID 的回卷。这是提前需要注意的。在 PostgreSQL 中,xid(事务 ID)和 oldestxid(最老活跃事务 ID)是事务系统的重要概念,每个事务 ID 左边的表示比它早的事务(past),右边的表示比它晚的事务(future)。
每个事务/子事务都有一个事务 ID,每行都有两个默认的隐藏属性 xmin 和 xmax,这两个属性分别保存了创建和更改它们的事务/子事务的 ID。MVCC 的要求就是每个会话只能看到比会话事务 ID 早且已经提交的事务修改的记录。由于 事务 ID 可以回卷,所以用环状表示更贴切一些。
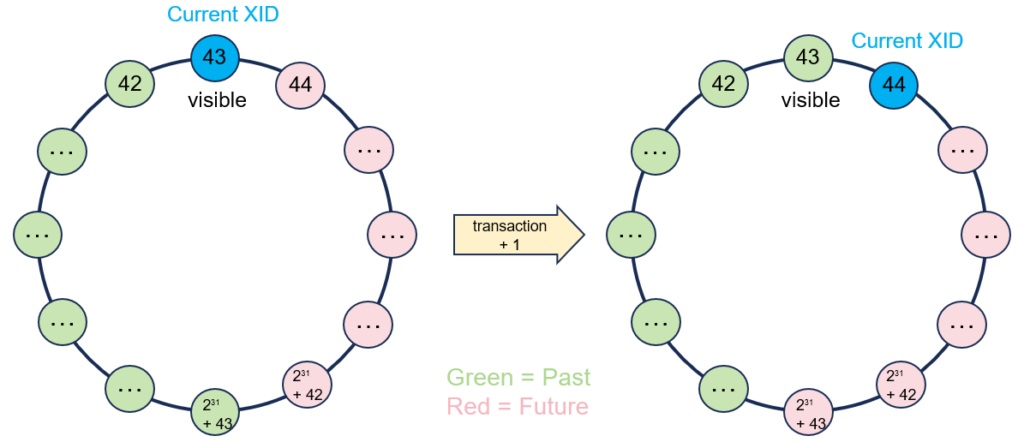
当没有发生事务 ID 回卷时,简单比较两个事务 ID 的大小是能判断先后的,但是当事务 ID 发生回卷后,上一个事务 ID 数字就会明显大于回卷后的事务ID,PG使用了函数转换为有符号32位数判断.
/*
* TransactionIdPrecedes --- is id1 logically < id2?
*/
bool TransactionIdPrecedes(TransactionId id1, TransactionId id2)
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}
核心作用是判断事务 ID id1 是否在逻辑上早于 id2,考虑到了事务 ID 循环(wraparound)的特性。输入:两个事务 ID id1 和 id2(均为 uint32 类型)。
输出:返回 true 表示 id1 逻辑上早于 id2,否则返回 false。如果是非普通事务 ID,直接按无符号整数比较(id1 < id2)。普通事务 ID 的比较(考虑循环),计算 id1 – id2 的差值,并将结果强制转换为 有符号 32 位整数(int32)。如果差值为负数(diff < 0),说明 id1 逻辑上早于 id2。
示例场景
id1 |
id2 |
id1 - id2(二进制) |
(int32)diff |
结果 |
|---|---|---|---|---|
| 5 | 10 | 0xFFFFFFFB | -5 | true |
| 10 | 5 | 0x00000005 | +5 | false |
| 4294967295 | 0 | 0xFFFFFFFF | -1 | true |
| 0 | 4294967295 | 0x00000001 | +1 | false |
通过转为有符号差值,可以自动处理回卷边界:
4294967295 – 0 = 0xFFFFFFFF,转为 int32 是 -1(表示 id1 更早)。
在设计上绝对禁止任意两个事务 ID 的差值绝对值超出 2^31 这个范围。换句话理论上当 PG 一个会话开启事务后,在数据库中最多有 2^31 (不是20亿)个事务比它早,最多有 2^31 个事务比它晚。注意,这并不表示实际还可以再开启 2^31 个事务。还能开多少个事务是由数据库中历史最早的那个未提交事务的事务 ID 决定。MVCC 需要比较会话的事务 ID 跟记录元组中的 xmin 和 xmax,它们间的差值也要在上面范围内。所以数据库表中记录的最早的事务 ID 也会制约后面的事务数量。
-
xmin:事务 ID,记录插入时的事务 ID。 -
xmax:事务 ID,记录删除或更新时的事务 ID。更新操作对应的删除和插入两笔记录。如果为 0,表示还没有删除或者删除事务还没有提交或者已回滚。删除也不会真的删除元组。
PG 冻结Freeze
PostgreSQL 用一种叫 事务 ID(Transaction ID, 简称 XID) 的数字来记录每一笔事务。每开始一个新事务,XID 就加 1。但这个数字不是无限大的——它最多只能到约 20亿(2³¹ – 1),之后就会“绕回”从头开始(就像老式里程表归零)。
- 把这些行标记为 “对所有未来事务都可见”。
- 这样,不管事务 ID 怎么绕圈,这些老数据都不会被误认为是“未来的”或“不可见的”。
给一本很老的书盖个章:“这本书永远有效,谁都能看。”
PG 冻结Freeze指扫描表的行,设置记录的标志位 t_infomask 为冻结状态( frozen )。同时在表的属性 relfrozenid 记录发起冻结会话的事务 ID。对于冻结状态的记录,在做事务 ID 比较的时候就不是跟 xmin 比较,而是跟表的 relfronzenid 比较。冻结操作是通过命令 vacuum 的 freeze 选项实现的。函数 age 方便直接计算表的年龄,具体就是看表的冻结事务 ID 的年龄,随着新事务不断产生,表的年龄也在快速增长。
SELECT c.oid::regclass as table_name, greatest(age(c.relfrozenxid), age(t.relfrozenxid)) as agefrom pg_class c left join pg_class t on c.reltoastrelid = t.oidwhere c.relkind in ('r', 'm') and c.relname like '%t1%'order by age desc ;
相关参数
$ sh show.sh|grep freeze autovacuum_freeze_max_age | 200000000 | Age at which to autovacuum a table to prevent transaction ID wraparound. autovacuum_multixact_freeze_max_age | 400000000 | Multixact age at which to autovacuum a table to prevent multixact wraparound. vacuum_freeze_min_age | 50000000 | Minimum age at which VACUUM should freeze a table row. vacuum_freeze_table_age | 150000000 | Age at which VACUUM should scan whole table to freeze tuples. vacuum_multixact_freeze_min_age | 5000000 | Minimum age at which VACUUM should freeze a MultiXactId in a table row. vacuum_multixact_freeze_table_age | 150000000 | Multixact age at which VACUUM should scan whole table to freeze tuples. $ sh show.sh|grep failsafe vacuum_failsafe_age | 1600000000 | Age at which VACUUM should trigger failsafe to avoid a wraparound outage. vacuum_multixact_failsafe_age | 1600000000 | Multixact age at which VACUUM should trigger failsafe to avoid a wraparound outage.
-
autovacuum:表示是否开启自动 vacuum操作。注意,即使是设置为off,为了避免事务 ID回卷带来大问题,PG依然会在合适的时机开启autovacuum。 -
vacuum_freeze_min_age:PG 认为事务年龄超过这个的就应该针对部分记录做 freeze操作。 -
vacuum_freeze_table_age:PG 认为事务年龄超过这个的就应该扫描全表做 freeze操作。 -
autovacuum_freeze_max_age:PG 认为事务年龄超过这个(默认2亿)就自动对表强制的发起 vacuum操作。 还有参数可降低自动vacuum操作对数据库读写的性能影响。 -
vacuum_failsafe_age:PG 认为事务年龄超过这个(默认值16亿)就强制对表发起不计成本(不考虑对数据库读写的性能影响,以及减少不必要的索引清理任务)的 vacuum操作。 PG 14 增加的参数。 - log_autovacuum_min_duration:是否在 PG 日志里记录
vacuum信息。默认是-1不记录,0记录
关键系统视图
| 视图/函数 | 用途 |
|---|---|
pg_stat_activity |
查看当前会话的 backend_xid 和 backend_xmin |
pg_prepared_xacts |
查看预备事务(2PC)的 xid |
pg_database |
查看数据库的 datfrozenxid(冻结事务 ID) |
txid_current() |
获取当前事务 ID |
pg_xact_status() |
查看事务 ID 状态(PostgreSQL 13+) |
查询当前事务 ID (xid)
当前会话的事务 ID
# SELECT txid_current(); -- 返回当前事务的 xid(仅当有写操作时才会分配)
# SELECT pg_current_xact_id();
pg_current_xact_id
--------------------
2518789
查看后台进程的事务 ID
SELECT pid, backend_xid, backend_xmin FROM pg_stat_activity WHERE backend_xid IS NOT NULL OR backend_xmin IS NOT NULL;
backend_xid:当前事务的 xid(如果有写操作)。
backend_xmin:当前事务可见的最老 xid(用于 MVCC 判断)。
查询最老活跃事务 (oldestxid)
# SELECT min(backend_xid::text::bigint) AS oldest_running_xid
FROM pg_stat_activity
WHERE backend_xid IS NOT NULL;
$ pg_controldata $PGDATA |grep -i xid
Latest checkpoint's NextXID: 0:2518790
Latest checkpoint's oldestXID: 750
Latest checkpoint's oldestXID's DB: 16393
Latest checkpoint's oldestActiveXID: 2518790
Latest checkpoint's oldestMultiXid: 1
Latest checkpoint's oldestCommitTsXid:0
Latest checkpoint's newestCommitTsXid:0
# SELECT
age(datfrozenxid) AS oldest_xid_age,
datname,2^31 - age(datfrozenxid) AS remaining_xids
FROM pg_database
ORDER BY oldest_xid_age DESC;
oldest_xid_age | datname | remaining_xids
----------------+-------------------------+----------------
2518040 | postgres | 2144965608
2518040 | template1 | 2144965608
2518040 | anbob | 2144965608
-- 表级
select oid, relname, relfrozenxid ,age(relfrozenxid) age, pg_current_xact_id()
from pg_class c
where c.relkind in ('r', 'm') and relfrozenxid <> 0 order by age desc limit 10;
oid | relname | relfrozenxid | age | pg_current_xact_id
-------+--------------+--------------+------+--------------------
16387 | t | 2514602 | 4190 | 2518792
75638 | test | 2514604 | 4188 | 2518792
16800 | utl_file_dir | 2514605 | 4187 | 2518792
2619 | pg_statistic | 2514606 | 4186 | 2518792
1247 | pg_type | 2514607 | 4185 | 2518792
17358 | test_listagg | 2514608 | 4184 | 2518792
17432 | t | 2514609 | 4183 | 2518792
26565 | j1_tbl | 2514610 | 4182 | 2518792
17481 | location | 2514611 | 4181 | 2518792
26570 | j2_tbl | 2514612 | 4180 | 2518792
(10 rows)
-- or --
SELECT c.relnamespace::regnamespace as schema_name, c.relname as table_name,
greatest(age(c.relfrozenxid), age(t.relfrozenxid)) as age,
2^31 - 1000000 - greatest(age(c.relfrozenxid), age(t.relfrozenxid)) as remaining
FROM pg_class c
LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
WHERE c.relkind IN ('r', 'm') ORDER BY 4;
schema_name | table_name | age | remaining
--------------------+-------------------------+------+------------
sys | t | 4191 | 2146479457
public | test | 4189 | 2146479459
utl_file | utl_file_dir | 4188 | 2146479460
...
datfrozenxid 是数据库的最老事务 ID(被冻结的 xid)。
- age(datfrozenxid) 计算当前事务 ID 与 datfrozenxid 的差距,如果接近 2 亿(autovacuum_freeze_max_age,默认 2 亿),需警惕 wraparound 风险。
检查长事务或慢SQL
SELECT datname, pid, usename, application_name,
client_addr, backend_start, xact_start, state_change,
waiting, query
FROM pg_stat_activity
WHERE ( now() - xact_start ) > '30 minutes'
OR ( now() - state_change ) > '10 minutes'
ORDER BY xact_start;
-- OR --
# SELECT datname, pid, usename, application_name,
client_addr, backend_start, xact_start, state_change,
wait_EVENT,WAIT_EVENT_TYPE, query
FROM pg_stat_activity
WHERE ( now() - xact_start ) > '30 minutes'
OR ( now() - state_change ) > '10 minutes'
ORDER BY xact_start;
datname | pid | usename | application_name | client_addr | backend_start | xact_start | state_change | wait_event | wait_event_type | q
uery
---------+---------+-----------------+------------------+---------------+-------------------------------+------------+-------------------------------+------------+-----------------+--
zXXXXX | 2417269 | zXXXXX_platform | | 172.20.23.152 | 2025-04-16 09:50:21.24521+08 | | 2025-05-10 12:32:56.67092+08 | ClientRead | Client | ;
zXXXXX| 2417276 | zXXXXX_platform | | 172.20.23.152 | 2025-04-16 09:50:42.25739+08 | | 2025-05-10 12:32:47.608168+08 | ClientRead | Client | ;
SELECT datname, pid, usename,
state, backend_xmin, xact_start
FROM pg_stat_activity
WHERE backend_xmin IS NOT NULL
ORDER BY age(backend_xmin) DESC;
datname | pid | usename | state | backend_xmin | xact_start
---------+--------+---------+--------+--------------+-------------------------------
highgo | 304909 | hg | active | 2518790 | 2025-05-23 17:40:45.535753+08
长事务除了手动处理终止外,可以配置timeout参数自动超时,一种主动的方式来处理长时间运行的事务,您可以:
- 将statement_timeout设置为一个大的值,让慢查询自动超时,或者
- 设置idle_in_transaction_session_timeout,让在一个打开的事务中空闲的会话超时退出,或者
- 将log_min_duration_statement设置为至少记录长时间运行的查询,以便您可以对它们设置警报,和手动终止它们。
从 pg_prepared_xacts 查看预备事务
SELECT gid, prepared, owner, database, transaction AS oldest_prepared_xid FROM pg_prepared_xacts;
检查事务 ID 耗尽
WITH max_age AS (
SELECT 2000000000 as max_old_xid
, setting AS autovacuum_freeze_max_age
FROM pg_catalog.pg_settings
WHERE name = 'autovacuum_freeze_max_age' )
, per_database_stats AS (
SELECT datname
, m.max_old_xid::int
, m.autovacuum_freeze_max_age::int
, age(d.datfrozenxid) AS oldest_current_xid
FROM pg_catalog.pg_database d
JOIN max_age m ON (true)
WHERE d.datallowconn )
SELECT max(oldest_current_xid) AS oldest_current_xid
, max(ROUND(100*(oldest_current_xid/max_old_xid::float))) AS percent_towards_wraparound
, max(ROUND(100*(oldest_current_xid/autovacuum_freeze_max_age::float))) AS percent_towards_emergency_autovac
FROM per_database_stats;
- percent_towards_wraparound 指标是设置警报的关键指标。检查它们是否真的处于耗尽点,它检查的上限(确切地说是 20 亿)小于导致耗尽的实际最大整数值。
- percent_towards_emergency_autovac 指标是我们建议监控的一个附加值,将监视数据库中达到 autovacuum_freeze_max_age 的最高事务 ID 值。这是一个用户可调的值,默认值为 2 亿,当任何表的最高事务 ID 值达到该值时,在该表上会启动一次更高优先级的自动清理。
对于每秒事务数很高的数据库,想要避免紧急清理期的频繁出现,对于每秒事务数很高的数据库,想要避免紧急清理期的频繁出现,增加 autovacuum_freeze_max_age 可能是有益的。增加此值的主要问题是,它可能会增加数据目录下 pg_xact 和 pg_commit_ts 文件夹中的存储空间。一般可以将此值设置为 10 亿。
修复事务 ID 耗尽
最简单(但不一定是最快)的方法是,强制对整个数据库集群进行一次清理,最好方法是用 PostgreSQL 附带的 vacuumdb 二进制实用程序。vaccumdb 不能在单用户下运行,如果小于100w只能单用户模式
vacuumdb --all --freeze --jobs=2 --echo --analyze
- –all 选项可确保对所有数据库都进行清理,因为事务 ID 是一个全局值。
- –freeze 选项可确保运行更激进的清理,以确保在该表中冻结尽可能多的元组,在未来的清理操作中,可以大大减少 IO 和 WAL 的产生。
- –jobs=2 允许并行运行多个清理。这应该设置在系统处理能力的范围内,以加快速度,但要小心设置得太高,增加磁盘使用率
- –echo 只是提供一些很小的反馈,以让您可以看到一些进度。
- –analyze 确保更新统计信息。如果很在意完成运行清理的时间,则可以将其关闭,稍后使用 –analyze-only 选项作为单独的步骤运行。
VACUUM 是一种定期性的数据库清理动作,会在 PostgreSQL 中执行。它有两种不同的形式;
| 运作方式 | VACUUM | VACUUM FULL |
|---|---|---|
| 方法 | 释放死行以供重用 | 重写没有死行的表 |
| Access Exclusive Lock | 否 | 是 |
| 空闲空间可用于 | 在同一个表内复用 | 归还操作系统 |
找检查表长事务或prepared transaction 并终止或rollback后,我们必须使数据库停机,以单用户模式连接,并对每个数据库执行 VACUUM FULL 操作。
$ pg_ctl stop $ postgres --single postgres backend> VACUUM FULL; $ postgres --single template1 backend> VACUUM FULL; ... 每个数据库上完成了 VACUUM FULL后正常启动 $ pg_ctl start
膨胀的表
SELECT schemaname, relname, n_live_tup, n_dead_tup, last_autovacuum
FROM pg_stat_all_tables
ORDER BY n_dead_tup
/ (n_live_tup
* current_setting('autovacuum_vacuum_scale_factor')::float8
+ current_setting('autovacuum_vacuum_threshold')::float8)
DESC
LIMIT 10;
如果 n_dead_tup 是0和 last_autovacuum 是null ,说明统计信息用问题,如果last_autovacuum is NULL需要配置autovacuum更积极。
避免事务回卷
在 PostgreSQL 中,可以使用各种重要方法来防止事务 ID 回卷。可以检查库级或表级age最大的对象或事务。定期做vacuum操作,结合数据库负载和大小做一些关于autovacuum或freezed参数调优,同时要有一套监控系统,用于告警及时的发送通知。