前不久整理了一《HighgoDB (PostgreSQL) %SYS CPU newfstatat() high 调优一例》, 这个问题还在持续,并且原因并不只是一个,从调了文件系统级atime,到调整wal size减少日志被动清理,还有在验证temp 文件,这里后来又发现了sysdate函数的timezone调用,简单记录。
前面有提到是newfsatat()函数产生的system CPU, 用于文件验证,这可能是因为是BClinux 22的原因,也有可能早期版本调用的是stat()函数。这里数据库是highgo DB v9 ARM.
分析思路
1,确认是系统级还是进程级
2,如果是PG进程,跟踪当时执行的命令
3,多并发回话,压力测试还原问题
4,使用strace 跟踪定位函数占用
5,使用strace跟踪函数调用的内容,如newfsatat()验证的是什么文件
6,根据操作的文件类型,判断相关功能。
相关命令
--确认进程id select pg_backend_pid(); -- 跟踪函数占比 strace -c -p xxx --跟踪进程 strace -p xxx -o str.log -- 查看文件调用 grep newfsatat str.log
使用捕捉的SQL 几个并发pgbench压测,负载如下,可见sys cpu使用近80%
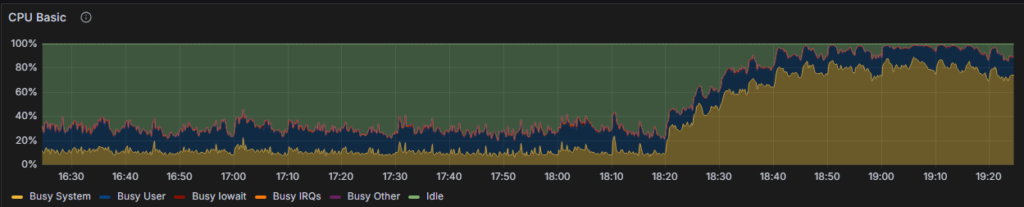
问题1, 产生的是pg_temp
$grep newfsatat xxx newfstatat(AT_FDCWD, "base/pgsql_tmp/pgsql_tmp.... newfstatat(AT_FDCWD, "base/pgsql_tmp/pgsql_tmp....
案例中一条3张表的left join 操作,调用了3000多次newfstatat调用,并且几乎全是pgsql_tmp的临时文件。
PostgreSQL 哪些使用临时文件
在数据库中的一些操作,可能会用到临时文件,比如排序,HASH JOIN, 聚合 , distinct , 中间结果存储等等。为了提高数据库的执行效率,一些操作可能会使用内存代替临时存储,仅仅当内存不足时使用临时文件。通过work_mem可以设置会话Query使用的临时内存的阈值,这里的临时都是Query执行过程中产生的临时文件,而不是临时表,通常临时空间在事务结束、Query结束后会自动回收。
加大work_mem 可以减少临时文件,配置参数temp_file_limit=0 可以把产生临时文件和SQL信息写到日志中。另外注意explain 执行计划中的Sort Method: external merge Disk: xxxkB,仅显示了一部分的临时文件使用情况,这里的实际情况是,explain 显示的是峰值使用量,而不是总使用量。
可以在视图pg_stat_database中看到数据库级别的统计信息,其中有temp_files和temp_bytes。这两列非常重要,因为它们会告诉您数据库是否必须向磁盘写入临时文件,这将不可避免地减慢操作速度。通常是因为work_mem设置太低,大量的低效SQL操作大数据,当时在创建索引等。
问题2,读取/etc/timezone
基于上面的问题我们压测是在tmp文件,查看执行计划使用的是hash join, 该join是会产生tmp, 我们在谓词列和join 列创建了索引,优化器使用了nest loop join而不是hash join, 结果不在产生temp, 再使用相同的负载压测,负载sys cpu缩少了一倍,近30%,但显然也不正常。
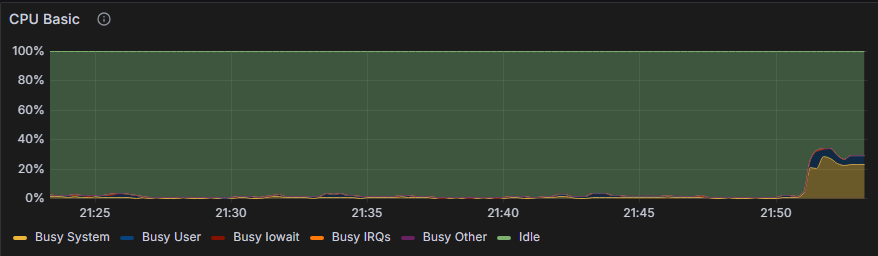
使用上面的方法继续strace跟踪,发现如下
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
...
note:
近几千次的/etc/localtime调用。判断应该是在做timezone相关调用,查看SQL 谓词条件有使用一个oracle兼容的函数sysdate, 取的是一个join 查询后日期字段(已创建索引 )最近8小时的记录,cdate> sysdate-to_dsinterval(‘0 8:00:00).
测试是否sysdate()和now()调用localtime
highgo=# select pg_backend_pid();
pg_backend_pid
----------------
785320
(1 row)
highgo=# select sysdate;
sysdate
-------------------
20250612 18:07:59
(1 row)
[{events=EPOLLIN, data={u32=669907864, u64=669907864}}], 1, -1, NULL, 8) = 1
recvfrom(12, "Q\0\0\0\25select sysdate;\0", 8192, 0, NULL, NULL) = 22
newfstatat(AT_FDCWD, "/etc/localtime", {st_mode=S_IFREG|0644, st_size=561, ...}, 0) = 0
sendto(11, "\2\0\0\0\300\3\0\0\216?\0\0\10\0\0\0\2\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 960, 0, NULL, 0) = 960
sendto(12, "T\0\0\0 \0\1sysdate\0\0\0\0\0\0\0\0\0#0\0\10\377\377\377\377\0"..., 81, 0, NULL, 0) = 81
recvfrom(12, 0xc03d58, 8192, 0, NULL, NULL) = -1 EAGAIN (Resource temporarily unavailable)
epoll_pwait(4,
highgo=# SELECT now();
now
-------------------------------
2025-06-12 18:08:10.254791+08
(1 row)
[{events=EPOLLIN, data={u32=669907864, u64=669907864}}], 1, -1, NULL, 8) = 1
recvfrom(12, "Q\0\0\0\22SELECT now();\0", 8192, 0, NULL, NULL) = 19
sendto(11, "\2\0\0\0@\0\0\0\216?\0\0\0\0\0\0\1\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 64, 0, NULL, 0) = 64
sendto(12, "T\0\0\0\34\0\1now\0\0\0\0\0\0\0\0\0\4\240\0\10\377\377\377\377\0\0D\0\0"..., 89, 0, NULL, 0) = 89
recvfrom(12, 0xc03d58, 8192, 0, NULL, NULL) = -1 EAGAIN (Resource temporarily unavailable)
epoll_pwait(4,
note:
验证了我的判断,在Highgo数据库中使用sysdate 需要调用newfstatat(AT_FDCWD, “/etc/localtime”), 而PostgreSQL原生的now函数并没有,而当前使用nl join后可能是关连的filter时,多过的调用了sysdate,而导致了问题的发生,继续 优化改为使用now(),继续压测。
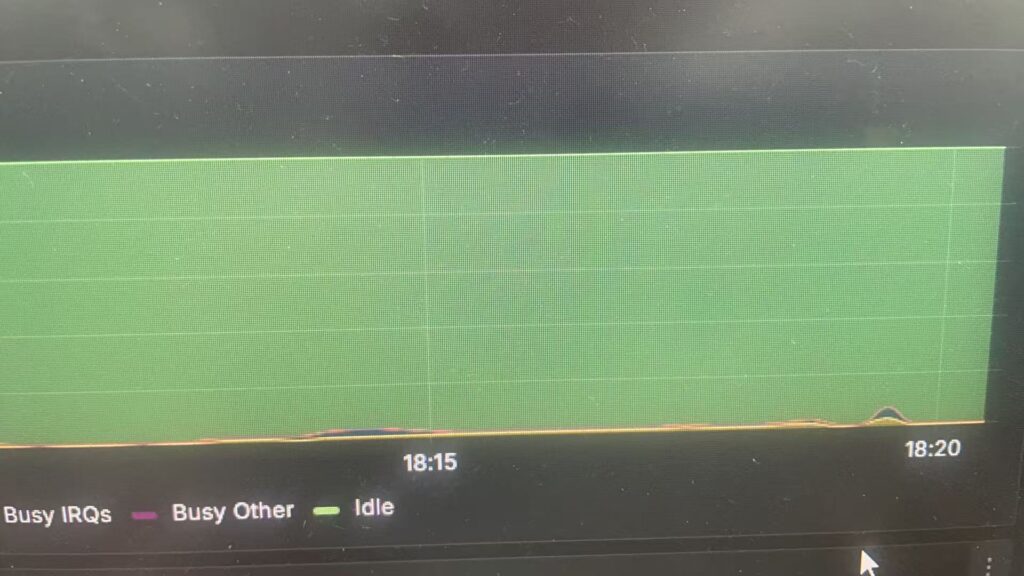
Note:
如果不放大看,几乎没有波动, sys CPU占用的问题得到解决,并且SQL整体的响应时间大大得到了优化提升。
— over —