OceanBase Database与Oracle一样支持分区表,但在使用时需要注意一些事项,因为它们在某些方面存在差异。分布式数据库的数据分布方式各不相同,在OceanBase中,数据根据分区规则分布到不同的物理区域。具体来说,在OceanBase中,数据以分区为粒度分布到不同的OB SERVER节点。
在Oracle模式下,OceanBase Database中的单表最多可以创建65536个分区或子分区。表的分区列也被称为分区键(partitioning key)。分区键必须是主键(PK)和唯一键(UK)的子集,换句话说,主键和唯一键必须包含分区键。
下面列几个oracle 迁移到oceanbase后的注意事项。
分区数据分布
在OB分区是数据同步的最小单元,每个分区的多副本组成一个独立的Paxos组,如果没有显示的创建分区表(non-partition),就可能认为只有1个分区。 默认业务只有leader副本提供读写服务,follower副本只同步数据不提供服务。特殊场景下,业务SQL使用弱一致性读 Hint(即read_consistency(weak))可以就近读取follower副本.
Paxos协议保证了Redo会在至少一个Follower副本同步(最终所有Follower副本一致)。多副本会跟OceanBase集群的rootservice服务维持心跳,当Leader副本不可用时,经过2个租约时间后rootservice会选举出新的Leader,应用一致新Leader提供读写服务。在OceanBase里,节点不分主从,同一节点中可能leader与flollwer混存,leader partition副本数据提供业务访问。
注,如果以下未表明Oceanbase MySQL Mode 均表示 Oracle mode。
分区格式
目前 Oracle mode of OceanBase Database支持分区类型:
- RANGE partitioning
- LIST partitioning
- HASH partitioning
- Composite partitioning
分区名转换 Partition naming conventions
对于LIST或RANGE分区表,在创建表时可以指定分区名称。然而,HASH分区表不允许指定分区名。在OceanBase V3中,不支持重命名分区(rename partition),这对依赖分区名的逻辑会有较大影响。如果分区名错误,只能删除后重建。在OceanBase V4中,这一限制已经被解决,用户可以直接重命名分区,这为分区管理提供了更大的灵活性。
分区转换 Convert non-partitioned into partitioned
在OceanBase V4中,可以像Oracle一样通过DDL的方式在非分区表和分区表(子分区表)之间进行转换。这意味着用户可以灵活地在不同的表类型之间切换,以满足不同的业务需求。
| Partitioning method | Non-partitioning | Partitioning | Subpartitioning |
|---|---|---|---|
| Non-partitioning | – | Supported | Supported |
| Partitioning | Not supported | – | Not supported |
| Subpartitioning | Not supported | Not supported | – |
样例如, 更多关注OB online doc obclient> ALTER TABLE tbl1 MODIFY PARTITION BY HASH(c1) PARTITIONS 4; Query OK, 0 rows affected obclient> ALTER TABLE tbl2 MODIFY PARTITION BY HASH(c1) SUBPARTITION BY RANGE(c2) SUBPARTITION template( SUBPARTITION p1 VALUES LESS THAN ('10-OCT-2016'), SUBPARTITION p2 VALUES LESS THAN ('30-OCT-2016')) PARTITIONS 2; Query OK, 0 rows affected
分区裁剪 Partition pruning
在OceanBase中,也可以使用分区裁剪技术来避免访问无关分区,从而减少无效读操作,提升SQL执行效率。然而,这要求SQL查询中必须包含分区键。用户可以通过 EXPLAIN 查看执行计划,从而确认分区裁剪的效果和执行情况
+------------------------------------------------------------------------------------+ | Query Plan | +------------------------------------------------------------------------------------+ | =============================================== | | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| | | ----------------------------------------------- | | |0 |TABLE FULL SCAN|TBL1|1 |4 | | | =============================================== | | Outputs & filters: | | ------------------------------------- | | 0 - output([TBL1.COL1], [TBL1.COL2]), filter([TBL1.COL1 = 1]), rowset=16 | | access([TBL1.COL1], [TBL1.COL2]), partitions(p1) | | is_index_back=false, is_global_index=false, filter_before_indexback[false], | | range_key([TBL1.__pk_increment]), range(MIN ; MAX)always true | +------------------------------------------------------------------------------------+
注:范围访问多分区的样式 access([T1.C1], [T1.C2]), partitions(p[0-4])
分区拆分 Parition Split
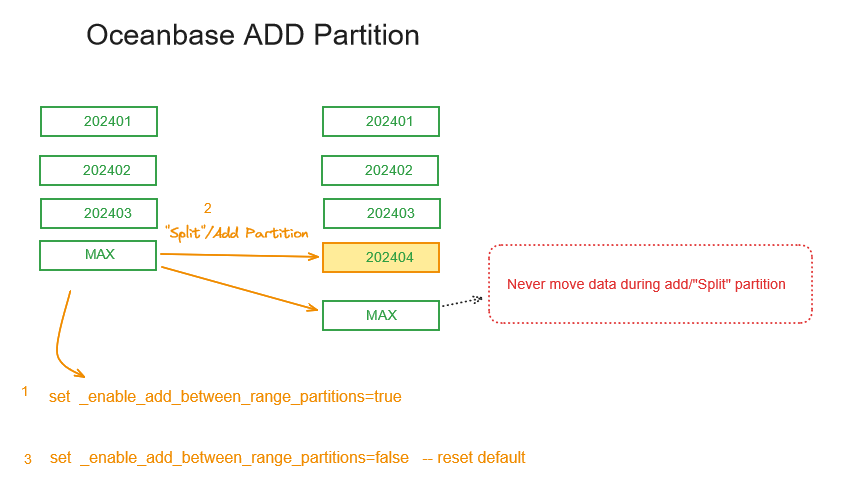
OceanBase 版本不支持split partition功能,仅支持顺序的add分区, 在oracle中可以从大的分区split 分区,增加中间的分区,在OB后期的版本增加了_enable_add_between_range_partitions隐藏参数,作为一个临时增加中间分区的开关,但是实现当前还是不够完美,split partition DDL语句中关键字依旧是”add partition”。
在oracle 中
ALTER TABLE table_name SPLIT PARTITION old_partition
AT (new_high_bound) INTO (PARTITION new_partition TABLESPACE new_tablespace,
PARTITION old_partition)
而在oceanbase中
# check parameter value
select b.tenant_name,a.* from
__all_virtual_tenant_parameter_info a,__all_tenant b where
name = '_enable_add_between_range_partitions' and
b.tenant_id > 1000 and a.tenant_id=b.tenant_id order by
1,zone;,
# set parameter to true as root
alter system set _enable_add_between_range_partitions = 'True' tenant='xxx';
# add betwen partition, e.g.
ALTER TABLE table_name add partition new_partition values less than (new_high_bound);
# check partition
select * from dba_tab_partitions where ....
# restore parameter to false as root
alter system set _enable_add_between_range_partitions = 'False' tenant='xxx';
1, 因为add partition 不校验数据,有可能数据在OLD PARTITION中
2,该操作不像oracle移动数据,不会导致索引失效, BTW 在OB中如果索引失效,如drop partitionr的全局索引,索引没有rebuild语法,需要提前获取索引的创建DDL, drop index, 重新创建。
Add between分区风险
对于每月有拆分分区需求的用户,添加区间分区时如果不校验数据,会存在一定风险。我们的一位客户在半年时间内因这个问题出现了两次核心数据库查询不一致的情况。试想一下,如上图数据先入库进入到MAX分区,然后拆分出202404分区,但实际202404匹配的数据依旧在MAX分区。而在查询时,如果SQL没有使用分区裁剪,扫描到MAX分区,数据是可以显示的,但如果优化器使用了分区裁剪,根据分区定义仅在202404分区检索,就会导致数据不显示。这时需要人为修正数据,将数据重新插入并删除MAX中的202404数据。这个问题在Oracle中 partition 交换不校验数据时也存在,9年前我分享了那个案例《数据去哪了?现实版 (partition data invalid)》
那么问题出在哪呢?
- 业务数据入库时间与前期设计不符,前端应用未做数据校验,如来自未来时间的数据。
- 数据库的split机制,在拆分区add时,未自动检索下一个分区区间的数据并移动匹配数据到对应分区。
- 进行split partition的DBA,在拆分add partition时没有提前手动检索下一个分区的数据。但对于每月有几十万个分区要拆分的客户来说,这又是不现实的。
- 是否不该增加MAX分区,无效数据就不应该入库?
要从源头上解决问题,建议:
- 前台对有效数据进行校验。
- 数据库增加SPLIT Partition并校验语法机制,或记录add between partition后台异步修正。
- 使用interval partition自动创建分区。
- 人工仅做数据修复。
Reference
https://en.oceanbase.com/docs/common-oceanbase-database-10000000001105739