Linux中的PostgreSQL内存
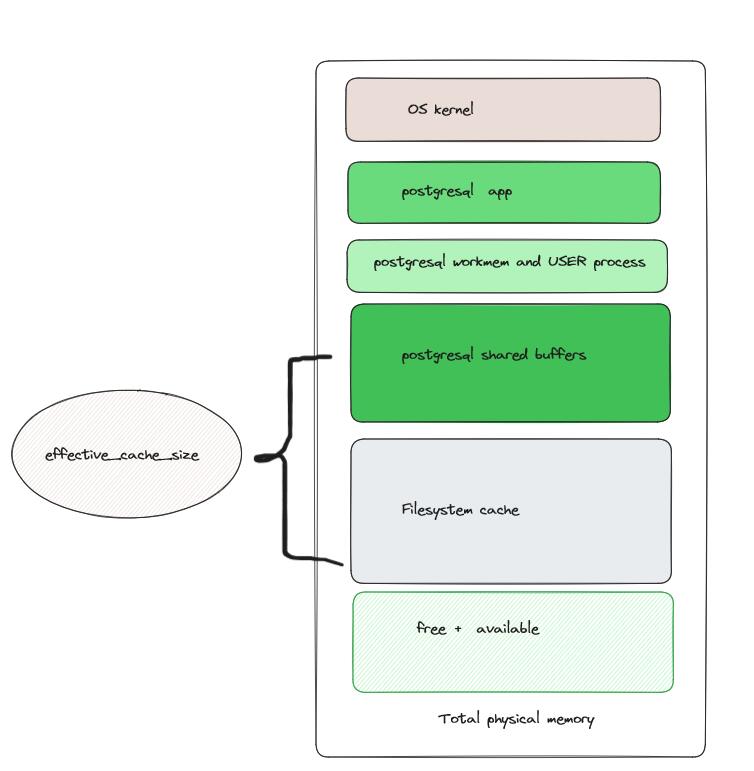
在Linux中PostgreSQL数据库数据内存使用,数据缓存通常称作双层缓存,在数据库层的shared_buffers和在操作系统的文件系统层还有文件系统cache,这点与oracle有所不同,如Oracle RAC生产使用ASM或raw device不使用文件系统,如果文件系统时通常建议filesystemio_options配置使用直接路径IO。在postgresql专用的linux服务器也会考虑给filesystem预留内存,还有一些和ORACLE PGA类似的work_mem及维护进程相关的内存。但大部分可能为成为文件系统缓存,以避免磁盘I/O,文件系统缓存是动态的. Linux平台PG内存大致如下:
PostgreSQL 优化器的作用
当用户发送SQL给PostgreSQL时,PG优化器会查找最优的执行方式生成“执行计划”,如访问路径、表JOIN方式等,但如何判断是否是最优执行计划,PostgresSQL和其它关系数据库一样,也是基于COST代价的算法,计算当前环境中算子的成本,如索引还是表扫描等。在数据库中除了业务数据以外在数据库内核参数也有一些配置,用于相同算子计划代价成本时因子,做为倾向性指引,如oracle数据库的optimizer_index_cost_adj和optimizer_index_caching,_index_prefetch_factor等,在PostgreSQL中优化器处理成本的方式其中之一是effective_cache_size。
了解effective_cache_size
PostgreSQL优化器是基于代价成本估算生成最优执行计划,成本的估算方式取决于各种因素:所需的 I/O 量、运算数量、返回数据量、选择率、统计信息等等,SQL的I/O 的成本是多少?这又取决于数据是否在内存中,PostgreSQL优化器如果知道多少内存区可以缓存数据,可以更好的选择执行计划,但是PostgreSQL系统知道数据库缓存配置shared_buffer,如果还能知道文件系统cache就可以更佳的规划缓存,调整I/O相关的执行计划,这时引入参数effective_cache_size。
effective_cache_size 是一个参数,用于设置当 PostgreSQL 计划执行查询时,操作系统缓存和 Postgres 的共享缓冲区中将容纳多少数据的估计值。 此值用于确定数据库引擎对磁盘 I/O 的依赖程度,简而言之是planner对单个查询可用的磁盘缓存的有效大小的假设,这对数据库性能有重大影响。值越高,越有可能使用索引扫描,值越低,越有可能使用顺序扫描。
Postgresql代码costsize.c中effective_cache_size
/*
* index_pages_fetched
* Estimate the number of pages actually fetched after accounting for
* cache effects.
*
* We use an approximation proposed by Mackert and Lohman, "Index Scans
* Using a Finite LRU Buffer: A Validated I/O Model", ACM Transactions
* on Database Systems, Vol. 14, No. 3, September 1989, Pages 401-424.
* The Mackert and Lohman approximation is that the number of pages
* fetched is
* PF =
* min(2TNs/(2T+Ns), T) when T <= b
* 2TNs/(2T+Ns) when T > b and Ns <= 2Tb/(2T-b)
* b + (Ns - 2Tb/(2T-b))*(T-b)/T when T > b and Ns > 2Tb/(2T-b)
* where
* T = # pages in table
* N = # tuples in table
* s = selectivity = fraction of table to be scanned
* b = # buffer pages available (we include kernel space here)
*
* We assume that effective_cache_size is the total number of buffer pages
* available for the whole query, and pro-rate that space across all the
* tables in the query and the index currently under consideration. (This
* ignores space needed for other indexes used by the query, but since we
* don't know which indexes will get used, we can't estimate that very well;
* and in any case counting all the tables may well be an overestimate, since
* depending on the join plan not all the tables may be scanned concurrently.)
*
* The product Ns is the number of tuples fetched; we pass in that
* product rather than calculating it here. "pages" is the number of pages
* in the object under consideration (either an index or a table).
* "index_pages" is the amount to add to the total table space, which was
* computed for us by make_one_rel.
*
* Caller is expected to have ensured that tuples_fetched is greater than zero
* and rounded to integer (see clamp_row_est). The result will likewise be
* greater than zero and integral.
*/
这个代码片段直接取自 costsize.c 的核心基本上是优化器中考虑effective_cache_size的地方,该公式仅用于估算索引的成本,如果 PostgreSQL 知道有大量的CACHE内存,假设更多的数据可以来自内存缓存,优化器使用索引的代价COST会更低(相对于seq scan全表扫),倾向使用索引扫描,实际当表足够大时可能才能观察到执行计划因为该参数计算的cost不同,产生的数据执行计划不同。
测试effective_cache_size影响 –pg 13
weejar=# show effective_cache_size
weejar-# ;
effective_cache_size
----------------------
4GB
weejar=# CREATE TABLE t_random AS SELECT id, random() AS r
weejar-# FROM generate_series(1, 1000000) AS id ORDER BY random();
SELECT 1000000
weejar=# CREATE TABLE t_ordered AS SELECT id, random() AS r
weejar-# FROM generate_series(1, 1000000) AS id;
SELECT 1000000
weejar=#
weejar=# CREATE INDEX idx_random ON t_random (id);
CREATE INDEX
weejar=# CREATE INDEX idx_ordered ON t_ordered (id);
CREATE INDEX
weejar=# VACUUM ANALYZE ;
VACUUM
weejar=# SET effective_cache_size TO '1 MB';
SET
weejar=# explain SELECT * FROM t_random WHERE id < 1000;
QUERY PLAN
----------------------------------------------------------------------------
Bitmap Heap Scan on t_random (cost=20.13..2554.64 rows=994 width=12)
Recheck Cond: (id < 1000) -> Bitmap Index Scan on idx_random (cost=0.00..19.88 rows=994 width=0)
Index Cond: (id < 1000)
weejar=# SET enable_bitmapscan TO off;
SET
weejar=# SET effective_cache_size TO '1 MB';
SET
weejar=# explain SELECT * FROM t_random WHERE id < 1000;
QUERY PLAN
---------------------------------------------------------------------------------
Index Scan using idx_random on t_random (cost=0.42..3949.80 rows=994 width=12)
Index Cond: (id < 1000)
weejar=# explain SELECT * FROM t_ordered WHERE id < 1000;
QUERY PLAN
---------------------------------------------------------------------------------
Index Scan using idx_ordered on t_ordered (cost=0.42..37.72 rows=931 width=12)
Index Cond: (id < 1000)
weejar=# SET effective_cache_size TO '1000 GB';
SET
weejar=# explain SELECT * FROM t_random WHERE id < 1000;
QUERY PLAN
---------------------------------------------------------------------------------
Index Scan using idx_random on t_random (cost=0.42..3673.80 rows=994 width=12)
Index Cond: (id < 1000)
weejar=# explain SELECT * FROM t_ordered WHERE id < 1000;
QUERY PLAN
---------------------------------------------------------------------------------
Index Scan using idx_ordered on t_ordered (cost=0.42..37.72 rows=931 width=12)
Index Cond: (id < 1000)
weejar=# SELECT correlation FROM pg_stats WHERE tablename = 't_ordered' AND attname = 'id';
correlation
-------------
1
weejar=# SELECT correlation FROM pg_stats WHERE tablename = 't_random' AND attname = 'id';
correlation
--------------
0.0020638437
Note:
我们看到对于t_random的表,索引扫描的代价cost在修改 effective_cache_size后发生改变,数字大小不是最重要的,而是相对的,因为执行计划的判断是根据大小在选择是seq scan还是index scan, effective_cache_size越小 ,seq scan的代价越小,PostgreSQL 将比其他方式更倾向于索引。
当然也有例外, Postgresql优化程序使用的表统计信息包含有关物理“correlation”的信息。如果correlation为 1(= 所有数据在磁盘上完美排序),effective_cache_size不会更改任何内容。( Hans-Jürgen Schönig指出如果只有一列,则情况也是如此).
在 PostgreSQL中建议effective_cache_size
effective_cache_size告诉PostgreSQL查询规划器在shared_buffers和文件系统缓存中估计有多少RAM可用于缓存数据。当设置这个参数时,你应该同时考虑PostgreSQL的共享缓冲区和内核磁盘缓存中用于PostgreSQL数据文件的部分,尽管有些数据可能同时存在于两个地方。另外,要考虑不同表上并发查询的预期数量,因为它们必须共享可用空间。该参数对PostgreSQL分配的共享内存大小没有影响,也不保留内核磁盘缓存;它仅用于评估目的。系统也不会假设查询之间的数据保留在磁盘缓存中。如果指定该值时没有单位,则以块为单位,effective_cache_size从pg 9.4从原来的128MB开始变为4GB。
Hans-Jürgen Schönig在blog中建议如果是PG专用服务器:
effective_cache_size = 物理内存 * 0.7
增加参数的值可能会导致内存中缓存更多数据,从而减少磁盘数量 读取必需内容并提高查询性能。在配置effective_cache_size时,重要的是要很好地了解系统的实际内存使用情况并找到合适的平衡点。
References