当两张大表做join访问时,我们希望优化器使用hash join的方式连接提高查询性能,但是在主流的oracle,mysql,postgresql或openGauss中表现稍有差异,所以在数据库替换时需要注意,简单记录一下对于equi join(=),non-equi-join(<>),Semijoin(exists), Antijoin(not exists/in), outer join(left/right join)时的不同表现。
Oracle
Oracle 对hash join的表关连支持较为丰富,但是oracle 的hash join 不支持 非等值条件, 下面只列几个不同数据库相比,此类型数据库JOIN不同的形为
SQL> explain plan for select count(a.name) from testa a,testb b where a.name=b.name;
Explained.
SQL> @x2
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------
Plan hash value: 26197381
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 22 | | 385 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 22 | | | |
|* 2 | HASH JOIN | | 100K| 2148K| 2248K| 385 (1)| 00:00:01 |
| 3 | TABLE ACCESS FULL | TESTA | 100K| 1074K| | 81 (2)| 00:00:01 |
| 4 | INDEX FAST FULL SCAN| IDX_TESTB_NAME | 100K| 1074K| | 85 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("A"."NAME"="B"."NAME")
SQL> explain plan for select /*+index(a)*/count(a.name) from testa a,testb b where a.name=b.name;
Explained.
SQL> @x2
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------
Plan hash value: 3352132728
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 22 | | 613 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 22 | | | |
|* 2 | HASH JOIN | | 100K| 2148K| 2248K| 613 (1)| 00:00:01 |
| 3 | INDEX FULL SCAN | IDX_TESTA_NAME | 100K| 1074K| | 308 (1)| 00:00:01 |
| 4 | INDEX FAST FULL SCAN| IDX_TESTB_NAME | 100K| 1074K| | 85 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("A"."NAME"="B"."NAME")
--也可以使用+index_ffs hint使用INDEX FAST FULL SCAN
SQL> explain plan for select /*+use_hash(t1,t2)*/ count(*) from t1 ,t2 where t1.a<>t2.a
2 ;
Explained.
SQL> @x2
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
Plan hash value: 916166457
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 104 | 26 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 104 | | |
| 2 | NESTED LOOPS | | 6642 | 674K| 26 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T1 | 82 | 4264 | 2 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL| T2 | 81 | 4212 | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("T1"."A"<>"T2"."A")
Hint Report (identified by operation id / Query Block Name / Object Alias):
Total hints for statement: 2 (U - Unused (2))
---------------------------------------------------------------------------
3 - SEL$1 / T1@SEL$1
U - use_hash(t1,t2)
4 - SEL$1 / T2@SEL$1
U - use_hash(t1,t2)
Note:
在Oracle中目前对于非=值的join条件还无法使用hash join.
MySQL
MySQL且在8.0.18中,引入hash join,但是和oracle一样还需要一个对等的条件(table1.a=table2.a)才能满足hash join。在8.0.20中,取消了对等条件的约束,可以全面支持non-equi-join,Semijoin,Antijoin,Left outer join/Right outer join。 官方样例
MYSQL_root@127.0.0.1 [anbob]> create table testa(id int,name varchar(20),addr varchar(3000), primary key(id));
Query OK, 0 rows affected (0.40 sec)
MYSQL_root@127.0.0.1 [anbob]> insert into testa
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM
cte WHERE n < 100000)
SELECT n,concat('anbob',n),rpad(n,100,'*') name FROM cte;
MYSQL_root@127.0.0.1 [anbob]> create table testc as select * from testa;
Query OK, 100000 rows affected (3.00 sec)
Records: 100000 Duplicates: 0 Warnings: 0
MYSQL_root@127.0.0.1 [anbob]> create index idx_testc on testc(name);
Query OK, 0 rows affected (1.15 sec)
Records: 0 Duplicates: 0 Warnings: 0
MYSQL_root@127.0.0.1 [anbob]> create index idx_testa on testa(name);
Query OK, 0 rows affected (1.62 sec)
Records: 0 Duplicates: 0 Warnings: 0
MYSQL_root@127.0.0.1 [anbob]> show index from testa;
+-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| testa | 0 | PRIMARY | 1 | id | A | 99212 | NULL | NULL | | BTREE | | | YES | NULL |
| testa | 1 | idx_testa | 1 | name | A | 99212 | NULL | NULL | YES | BTREE | | | YES | NULL |
+-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.00 sec)
MYSQL_root@127.0.0.1 [anbob]> show index from testc;
+-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| testc | 1 | idx_testc | 1 | name | A | 99203 | NULL | NULL | YES | BTREE | | | YES | NULL |
+-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
1 row in set (0.01 sec)
MYSQL_root@127.0.0.1 [anbob]> select version();
+-------------------+
| version() |
+-------------------+
| 8.0.20-commercial |
+-------------------+
1 row in set (0.00 sec)
MYSQL_root@127.0.0.1 [anbob]> show variables like '%optimizer_switch%' \G
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,
engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,
batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,
subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,
use_invisible_indexes=off,skip_scan=on,hash_join=on
1 row in set (0.00 sec)
MYSQL_root@127.0.0.1 [anbob]> explain format=tree select count(*) from testa a join testc c on a.name=c.name;
+----------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+----------------------------------------------------------------------------------------------------------------------------------------+
| -> Aggregate: count(0)
-> Nested loop inner join (cost=118728.20 rows=99203)
-> Filter: (c.`name` is not null) (cost=10168.55 rows=99203)
-> Index scan on c using idx_testc (cost=10168.55 rows=99203)
-> Index lookup on a using idx_testa (name=c.`name`) (cost=0.99 rows=1)
|
+--------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
## Use NO_INDEX() hint to force hash join to be used
MYSQL_root@127.0.0.1 [anbob]> explain format=tree select /*+no_index(a) no_index(c)*/ count(*) from testa a join testc c on a.name=c.name;
+--------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+--------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Aggregate: count(0)
-> Inner hash join (a.`name` = c.`name`) (cost=984230411.40 rows=99203)
-> Table scan on a (cost=0.07 rows=99212)
-> Hash
-> Table scan on c (cost=10168.55 rows=99203)
|
+--------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
MYSQL_root@127.0.0.1 [anbob]> explain format=tree select count(*) from testa a join testc c on a.name<>c.name;
+------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+------------------------------------------------------------------------------------------------------------------+
| -> Aggregate: count(0)
-> Filter: (a.`name` <> c.`name`) (cost=984230411.40 rows=8857914998)
-> Inner hash join (no condition) (cost=984230411.40 rows=8857914998)
-> Index scan on a using idx_testa (cost=0.16 rows=99212)
-> Hash
-> Index scan on c using idx_testc (cost=10168.55 rows=99203)
|
+------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)

hash join 也并不是总比NL join性能优,取决于对表数据的选择率selectivity, 且在mysql 8新的版本迭代中hash join的性能也可能有提升。
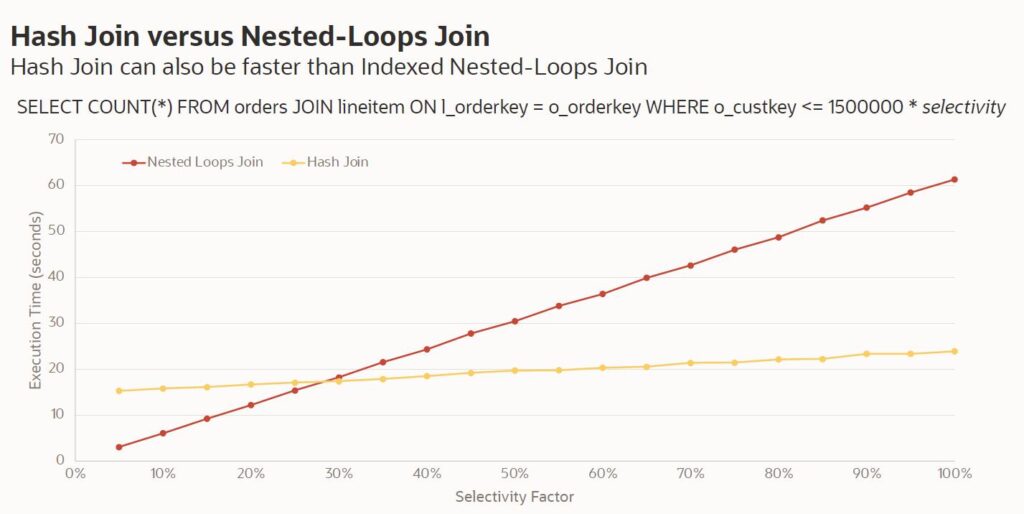
Hash join in MySQL 8.0 gives better join performance when • No index is available • Query is IO-bound • Large part of a table will be accessed • Selective conditions on multiple tables
Note:
注意在mysql中使用hash join 关连的列上不能使用index, 对于<>操作是个例外,它及能使用index也能使用hash join, 所以如果我们按照oracle的优化思路, 通常对于大表join的列上建议创建索引,而在mysql中可能会导致性能下降, 有hash join变化nest loop join , 关于 8.0 hash join PPT更多可以查看这里
Postgresql 13
anbob=# explain select count(a.name) from testa a,testc b where a.name=b.name;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Aggregate (cost=2319.70..2319.71 rows=1 width=8)
-> Hash Join (cost=280.90..2294.70 rows=10000 width=10)
Hash Cond: ((a.name)::text = (b.name)::text)
-> Index Only Scan using testa_name_idx on testa a (cost=0.42..1539.22 rows=100000 width=10)
-> Hash (cost=155.48..155.48 rows=10000 width=9)
-> Index Only Scan using idx_testc_uppname2 on testc b (cost=0.29..155.48 rows=10000 width=9)
(6 行记录)
anbob=# explain select count(a.name) from testa a,testc b where a.name=b.name;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Aggregate (cost=2319.70..2319.71 rows=1 width=8)
-> Hash Join (cost=280.90..2294.70 rows=10000 width=10)
Hash Cond: ((a.name)::text = (b.name)::text)
-> Index Only Scan using testa_name_idx on testa a (cost=0.42..1539.22 rows=100000 width=10)
-> Hash (cost=155.48..155.48 rows=10000 width=9)
-> Index Only Scan using idx_testc_uppname2 on testc b (cost=0.29..155.48 rows=10000 width=9)
(6 行记录)
anbob=# explain select count(a.name) from testa a,testc b where a.name<>b.name;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=12730580.84..12730580.85 rows=1 width=8)
-> Gather (cost=12730580.63..12730580.84 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=12729580.63..12729580.64 rows=1 width=8)
-> Nested Loop (cost=0.70..11687924.38 rows=416662500 width=10)
Join Filter: ((a.name)::text <> (b.name)::text)
-> Parallel Index Only Scan using testa_name_idx on testa a (cost=0.42..955.88 rows=41667 width=10)
-> Index Only Scan using idx_testc_uppname2 on testc b (cost=0.29..155.48 rows=10000 width=9)
(8 行记录)
anbob=# explain select * from testa a where exists(select 1 from testc b where a.name=b.name) ;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Hash Semi Join (cost=280.49..2195.24 rows=10000 width=14)
Hash Cond: ((a.name)::text = (b.name)::text)
-> Seq Scan on testa a (cost=0.00..1541.00 rows=100000 width=14)
-> Hash (cost=155.48..155.48 rows=10000 width=9)
-> Index Only Scan using idx_testc_uppname2 on testc b (cost=0.29..155.48 rows=10000 width=9)
(5 行记录)
anbob=# explain select * from testa a where not exists(select 1 from testc b where a.name=b.name) ;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Hash Anti Join (cost=280.49..2995.24 rows=90000 width=14)
Hash Cond: ((a.name)::text = (b.name)::text)
-> Seq Scan on testa a (cost=0.00..1541.00 rows=100000 width=14)
-> Hash (cost=155.48..155.48 rows=10000 width=9)
-> Index Only Scan using idx_testc_uppname2 on testc b (cost=0.29..155.48 rows=10000 width=9)
(5 行记录)
openGauss 5
anbob=# explain select /*+ hashjoin(a b) */ count(a.name) from testa a,testb b where a.name=b.name;
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Aggregate (cost=6304.01..6304.02 rows=1 width=18)
-> Hash Join (cost=1296.45..6068.01 rows=94401 width=10)
Hash Cond: ((a.name)::text = (b.name)::text)
-> Index Only Scan using idx_name on testa a (cost=0.00..3077.55 rows=200000 width=10)
-> Hash (cost=716.09..716.09 rows=46429 width=10)
-> Index Only Scan using idx_testb_name on testb b (cost=0.00..716.09 rows=46429 width=10)
(6 rows)
anbob=# explain select /*+ hashjoin(a b) */ count(a.name) from testa a,testb b where a.name<>b.name;
WARNING: unused hint: HashJoin(a b)
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Aggregate (cost=162505173.71..162505173.72 rows=1 width=18)
-> Nested Loop (cost=0.00..139290909.71 rows=9285705599 width=10)
Join Filter: ((a.name)::text <> (b.name)::text)
-> Index Only Scan using idx_name on testa a (cost=0.00..3077.55 rows=200000 width=10)
-> Materialize (cost=0.00..948.23 rows=46429 width=10)
-> Index Only Scan using idx_testb_name on testb b (cost=0.00..716.09 rows=46429 width=10)
(6 rows)
anbob=# explain select /*+hashjoin(a b)*/ * from testa a where not exists(select 1 from testb b where a.name=b.name);
QUERY PLAN
------------------------------------------------------------------------------------------------------
Hash Anti Join (cost=1296.45..6065.64 rows=105599 width=14)
Hash Cond: ((a.name)::text = (b.name)::text)
-> Seq Scan on testa a (cost=0.00..3082.00 rows=200000 width=14)
-> Hash (cost=716.09..716.09 rows=46429 width=10)
-> Index Only Scan using idx_testb_name on testb b (cost=0.00..716.09 rows=46429 width=10)
(5 rows)
anbob=# explain select /*+hashjoin(a b)*/ * from testa a where exists(select 1 from testb b where a.name=b.name);
QUERY PLAN
------------------------------------------------------------------------------------------------------
Hash Semi Join (cost=1296.45..5953.66 rows=94401 width=14)
Hash Cond: ((a.name)::text = (b.name)::text)
-> Seq Scan on testa a (cost=0.00..3082.00 rows=200000 width=14)
-> Hash (cost=716.09..716.09 rows=46429 width=10)
-> Index Only Scan using idx_testb_name on testb b (cost=0.00..716.09 rows=46429 width=10)
(5 rows)
anbob=# explain select /*+hashjoin(a b) indexscan(a)*/ * from testa a where exists(select 1 from testb b where a.name=b.name) ;
QUERY PLAN
------------------------------------------------------------------------------------------------------
Hash Semi Join (cost=1296.45..6057.41 rows=94401 width=14)
Hash Cond: ((a.name)::text = (b.name)::text)
-> Index Scan using idx_name on testa a (cost=0.00..3185.75 rows=200000 width=14)
-> Hash (cost=716.09..716.09 rows=46429 width=10)
-> Index Only Scan using idx_testb_name on testb b (cost=0.00..716.09 rows=46429 width=10)
(5 rows)
Note:
在PostgreSQL和openGauss当前版本中和oracle较为接近, 同样<>无法使用 join,其它可以hash join也可以使用index [only] scan.
| equi-join(=) | non-equi-join(<>) | Semijoin(exists) | Antijoin(not exists/in) | outer join(left/right join) | |
| oracle | yes | no | yes | yes | yes |
| mysql8.20 | yes① | yes | yes② | yes② | yes② |
| Postgresql13 | yes | no | yes | yes | yes |
| openGauss5 | yes | no | yes | yes | yes |
| OceanbaseV3 | yes | no | yes | yes | yes |
| ①列上无索引 | |||||
| ②内表不使用索引 |
OCEANBASE
# ob for mysql obclient [test]> select version(); +---------------------------+ | version() | +---------------------------+ | 5.7.25-OceanBase-v3.2.4.0 | +---------------------------+ 1 row in set (0.002 sec) obclient [test]> explain select count(*) from testa a join testc c on a.name=c.name\G *************************** 1. row *************************** Query Plan: ======================================================== |ID|OPERATOR |NAME |EST. ROWS|COST | -------------------------------------------------------- |0 |SCALAR GROUP BY | |1 |116329| |1 | MERGE JOIN | |97689 |112600| |2 | PX COORDINATOR | |100000 |47986 | |3 | EXCHANGE OUT DISTR|:EX10000 |100000 |38681 | |4 | TABLE SCAN |c(idx_testc)|100000 |38681 | |5 | TABLE SCAN |a(idx_testa)|100000 |38681 | ======================================================== obclient [test]> explain select /*+full(a) full(c)*/ count(*) from testa a join testc c on a.name=c.name\G *************************** 1. row *************************** Query Plan: ==================================================== |ID|OPERATOR |NAME |EST. ROWS|COST | ---------------------------------------------------- |0 |SCALAR GROUP BY | |1 |267277| |1 | HASH JOIN | |108800 |263125| |2 | PX COORDINATOR | |100001 |47986 | |3 | EXCHANGE OUT DISTR|:EX10000|100001 |38681 | |4 | TABLE SCAN |c |100001 |38681 | |5 | TABLE SCAN |a |111373 |47918 | ==================================================== obclient [test]> explain select count(*) from testa a join testc c on a.name<>c.name\G *************************** 1. row *************************** Query Plan: ============================================================== |ID|OPERATOR |NAME |EST. ROWS |COST | -------------------------------------------------------------- |0 |SCALAR GROUP BY | |1 |4075097142| |1 | NESTED-LOOP JOIN | |9899903312|3697255733| |2 | TABLE SCAN |a(idx_testa)|100000 |38681 | |3 | MATERIAL | |100000 |49286 | |4 | PX COORDINATOR | |100000 |47986 | |5 | EXCHANGE OUT DISTR|:EX10000 |100000 |38681 | |6 | TABLE SCAN |c(idx_testc)|100000 |38681 | ============================================================== obclient [test]> explain select /*+ full(a) full(c) */ count(*) from testa a right join testc c on a.name=c.name\G *************************** 1. row *************************** Query Plan: ==================================================== |ID|OPERATOR |NAME |EST. ROWS|COST | ---------------------------------------------------- |0 |SCALAR GROUP BY | |1 |267277| |1 | HASH OUTER JOIN | |108800 |263125| |2 | PX COORDINATOR | |100001 |47986 | |3 | EXCHANGE OUT DISTR|:EX10000|100001 |38681 | |4 | TABLE SCAN |c |100001 |38681 | |5 | TABLE SCAN |a |111373 |47918 | ==================================================== obclient [test]> explain select /*+ full(a) */ count(*) from testa a where not exists(select /*+full(c)*/ 1 from testc c where a.name=c.name)\G *************************** 1. row *************************** Query Plan: ==================================================== |ID|OPERATOR |NAME |EST. ROWS|COST | ---------------------------------------------------- |0 |SCALAR GROUP BY | |1 |244381| |1 | HASH ANTI JOIN | |1000 |244342| |2 | TABLE SCAN |a |100000 |38681 | |3 | PX COORDINATOR | |100000 |47986 | |4 | EXCHANGE OUT DISTR|:EX10000|100000 |38681 | |5 | TABLE SCAN |c |100000 |38681 | ==================================================== obclient [test]> explain select /*+ full(a) */ count(*) from testa a where exists(select /*+full(c)*/ 1 from testc c where a.name=c.name)\G *************************** 1. row *************************** Query Plan: ==================================================== |ID|OPERATOR |NAME |EST. ROWS|COST | ---------------------------------------------------- |0 |SCALAR GROUP BY | |1 |239082| |1 | HASH RIGHT SEMI JOIN| |110 |239078| |2 | PX COORDINATOR | |100001 |47986 | |3 | EXCHANGE OUT DISTR|:EX10000|100001 |38681 | |4 | TABLE SCAN |c |100001 |38681 | |5 | TABLE SCAN |a |111373 |47918 | ====================================================
Note:
OBmysql虽然是5.7 mysql,但是在OB中同样支持hash join. 但是<> 默认没有和mysql 8一样使用hash join,即使增加full 和use_hash hint。其他同样支持SEMI 、 ANTI 、 OUTER的 HASH JOIN
# OB for oracle obclient [TBCS]> explain select count(a.name) from testa a join testc c on a.name=c.name\G *************************** 1. row *************************** Query Plan: ======================================================== |ID|OPERATOR |NAME |EST. ROWS|COST | -------------------------------------------------------- |0 |SCALAR GROUP BY | |1 |132984| |1 | MERGE JOIN | |103890 |129019| |2 | TABLE SCAN |A(IDX_TESTA)|99999 |38681 | |3 | PX COORDINATOR | |99999 |47985 | |4 | EXCHANGE OUT DISTR|:EX10000 |99999 |38681 | |5 | TABLE SCAN |C(IDX_TESTC)|99999 |38681 | ========================================================
note:
OBoracle对于= 没有像oracle一样使用hash join index,而是merge join加分布式并行的方法.
在不同的数据库中对于表相同数据,join可能会产生不同的形为方式,即使是语法兼容也可能产生较大的性能差异, 尤其是在使用hint时,今天发现一个use_nl hint在达梦数据库上的不同表现,导致错误的认为达梦比oracle差了几百倍的性能,回头有达梦环境测试一下。数据库替换任重道远。
注: 如果发现不对之处请联系我。