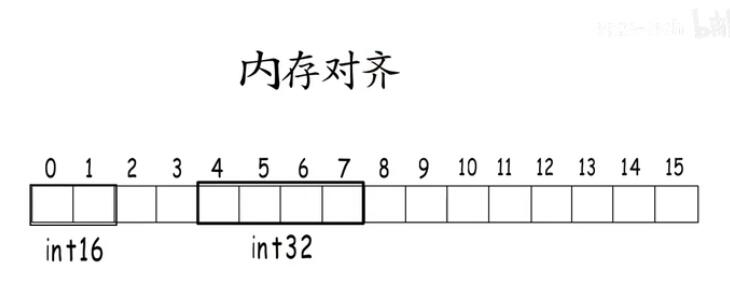
在创建表时,如果相同的列类型,不同表列的顺序是否会影响数据库占用空间大小?使用oracle、mysql或postgresql是不是相同的表现呢? 不是的Postgresql近期发现空间使用会因为columns的顺序而占用不同的大小,当然也和实际的数据有关,简单的测试。
# oracle
SQL> CREATE TABLE t_test ( i1 int,
i2 int,
i3 int,
v1 varchar(100),
v2 varchar(100),
v3 varchar(100)
7 );
Table created.
INSERT INTO t_test SELECT 10, 20, 30,
'abcd', 'abcd', 'abcd'
3 FROM dual connect by rownum<=10000; 10000 rows created. SQL> select BYTES from dba_segments where segment_name='T_TEST';
BYTES
----------
393216
SQL> SELECT dbms_xplan.FORMAT_SIZE(BYTES) SEG_SIZE from dba_segments where segment_name='T_TEST';
SEG_SIZE
------------------------------
384K
SQL> DROP TABLE T_TEST;
Table dropped.
SQL> CREATE TABLE t_test ( v1 varchar(100),
i1 int,
v2 varchar(100),
i2 int,
v3 varchar(100),
i3 int
7 );
Table created.
SQL> INSERT INTO t_test SELECT 'abcd', 10, 'abcd',
20, 'abcd', 30
3 FROM dual connect by rownum<=10000; SQL> select BYTES from dba_segments where segment_name='T_TEST';
BYTES
----------
393216
Note:
在ORACLE数据库中TABLE COLUMN顺序打乱后, 表段大小一致。
# MySQL
mysql> create table t_test( i1 int,i2 int, i3 int,v1 varchar(100),v2 varchar(100),v3 varchar(100));
Query OK, 0 rows affected (0.09 sec)
mysql> DELIMITER $$
mysql> CREATE PROCEDURE LoadCal()
-> BEGIN
-> declare n int default 1;
-> declare MAX int default 10001;
-> while n < MAX do -> insert into t_test select 10,20,30,'abcd','abcd','abcd';
-> set n = n + 1;
-> end while;
-> END$$
Query OK, 0 rows affected (0.02 sec)
mysql> DELIMITER ;
mysql> select count(*) from t_test;
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)
mysql> call LoadCal();
Query OK, 1 row affected (1 min 17.73 sec)
mysql> select count(*) from t_test;
+----------+
| count(*) |
+----------+
| 10000 |
+----------+
1 row in set (0.05 sec)
mysql> SELECT TABLE_NAME ,
-> CONCAT(ROUND((DATA_LENGTH)/1024,2),'KB') AS'total'
-> FROM information_schema.TABLES WHERE TABLE_NAME='t_test';
+------------+-----------+
| TABLE_NAME | total |
+------------+-----------+
| t_test | 1552.00KB |
+------------+-----------+
1 row in set (0.00 sec)
mysql> drop table t_test;
Query OK, 0 rows affected (0.04 sec)
mysql> create table t_test( v1 varchar(100),i1 int, v2 varchar(100),i2 int,v3 varchar(100),i3 int);
Query OK, 0 rows affected (0.05 sec)
mysql> drop procedure LoadCal;
Query OK, 0 rows affected (0.03 sec)
mysql> DELIMITER $$
mysql> CREATE PROCEDURE LoadCal()
-> BEGIN
-> declare n int default 1;
-> declare MAX int default 10001;
-> while n < MAX do -> insert into t_test select 'abcd',10,'abcd',20,'abcd',30 ;
-> set n = n + 1;
-> end while;
-> END$$
Query OK, 0 rows affected (0.02 sec)
mysql> DELIMITER ;
mysql> call LoadCal;
Query OK, 1 row affected (1 min 15.33 sec)
mysql> SELECT TABLE_NAME ,
-> CONCAT(ROUND((DATA_LENGTH)/1024,2),'KB') AS'total'
-> FROM information_schema.TABLES WHERE TABLE_NAME='t_test';
+------------+-----------+
| TABLE_NAME | total |
+------------+-----------+
| t_test | 1552.00KB |
+------------+-----------+
1 row in set (0.00 sec)
Note:
MySQL数据库,表列不同的顺序,表所占用空间大小也是一致。
# PostGreSQL
anbob=# CREATE TABLE t_test ( i1 int,
anbob(# i2 int,
anbob(# i3 int,
anbob(# v1 varchar(100),
anbob(# v2 varchar(100),
anbob(# v3 varchar(100)
anbob(# );
CREATE TABLE
anbob=# INSERT INTO t_test SELECT 10, 20, 30,
anbob-# 'abcd', 'abcd', 'abcd'
anbob-# FROM generate_series(1, 10000);
INSERT 0 10000
anbob=# select pg_relation_size('t_test');
pg_relation_size
------------------
606208
(1 row)
anbob=# select pg_size_pretty( pg_relation_size('t_test'));
pg_size_pretty
----------------
592 kB
(1 row)
anbob=# drop table t_test;
DROP TABLE
anbob=# CREATE TABLE t_test ( v1 varchar(100),
anbob(# i1 int,
anbob(# v2 varchar(100),
anbob(# i2 int,
anbob(# v3 varchar(100),
anbob(# i3 int
anbob(# );
CREATE TABLE
anbob=# INSERT INTO t_test SELECT 'abcd', 10, 'abcd',
anbob-# 20, 'abcd', 30
anbob-# FROM generate_series(1, 10000);
INSERT 0 10000
anbob=# select pg_size_pretty( pg_relation_size('t_test'));
pg_size_pretty
----------------
672 kB
(1 row)
Note:
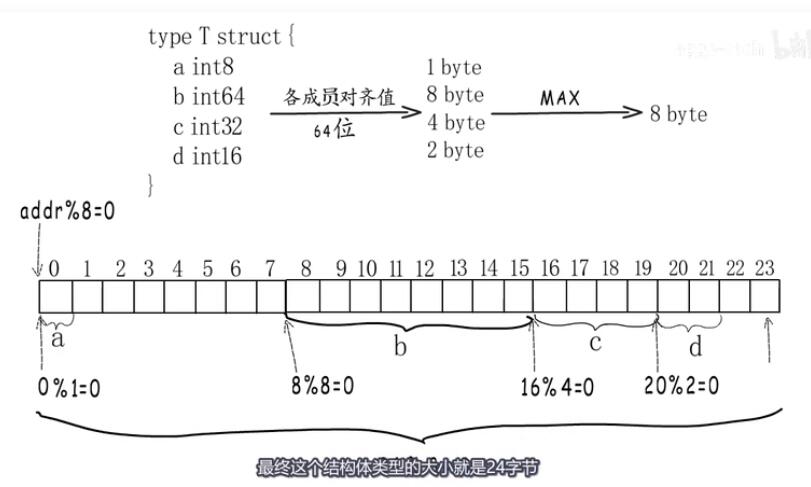
在PostgreSQL数据中,尽管表中的数据完全相同,但该表已显着增长。 这个问题的原因称为alignment(对齐)。PostgreSQL tuple内部有ALIGN机制,因此字段顺序也有讲究,选择不好,可能因为ALIGN导致空间放大, 理论如下:如果一个字段没有以CPU word-size的倍数开始,那么 CPU 就会遇到困难,在代码src/backend/access/common/heaptuple.c。 因此,PostgreSQL 会相应地在物理上对齐数据。 这里最重要的一点是,将具有相似数据类型的列彼此相邻分组是有意义的。 当然,结果和潜在的大小差异在很大程度上取决于内容。 如果在此示例中使用“abc”而不是“abcd”,则结果不会显示任何差异;
weejar=# select pg_column_size(row(int4 '10',varchar 'abc',int4 '10',varchar 'abc'));
pg_column_size
----------------
40
-- 24+4+4+4+4
weejar=# select pg_column_size(row(int4 '10',int4 '10',varchar 'abc',varchar 'abc'));
pg_column_size
----------------
40
typalign char
typalign is the alignment required when storing a value of this type. It applies to storage on disk as well as most representations of the value inside PostgreSQL. When multiple values are stored consecutively, such as in the representation of a complete row on disk, padding is inserted before a datum of this type so that it begins on the specified boundary. The alignment reference is the beginning of the first datum in the sequence. Possible values are:
c = char alignment, i.e., no alignment needed.
s = short alignment (2 bytes on most machines).
i = int alignment (4 bytes on most machines).
d = double alignment (8 bytes on many machines, but by no means all).
weejar=# select pg_column_size(row(varchar 'abc'));
pg_column_size
----------------
28
weejar=# select pg_column_size(row(int4 '10'));
pg_column_size
----------------
28
weejar=# select pg_column_size(row(varchar 'abcd'));
pg_column_size
----------------
29
weejar=# select pg_column_size(row(varchar 'abcd',int4 '10'));
pg_column_size
----------------
36
Note:
36= header + “abcd” 5 取4倍数为8+int4 4
= 24+4+[1+(3补齐)}+4
在C或Go Lang开发对象中同样存在该设计,如GO
查看这个表的对齐规则
SELECT a.attname, t.typname, t.typalign, t.typlen FROM pg_class c JOIN pg_attribute a ON (a.attrelid = c.oid) JOIN pg_type t ON (t.oid = a.atttypid) WHERE c.relname = 'xxx' AND a.attnum >= 0 ORDER BY a.attnum;
Summary:
测试发现目前只有postgresql会因为补齐问题,在相同数据不同的列顺序时会产生不同的空间大小,而oracle和MySQL不存在,所以在PostgreSQL中注意列顺序,同时在opengauss系也和PG相同的表现。
by the way, 对于10000行相同的数据也可以看出三个数据库的磁盘空间耗费排列 MySQL (1500K)> PostgreSQL (600K) > Oracle (300K)