enq:CR – block range reuse ckpt 出现该问题时分析等待链通常是前台进程等待CKPT进程在完成checkpoint, 通常是在DBWR进程在争用CPU或I/O 性能时,通常该event会非常短暂,如果该event已经在AWR dbtime中占据了较大占比时,需要引起关注。通常还伴随enq: RO – fast object reuse event, 当时如果做select 在内的DML SQL可能还出现library cache lock,等待ckpt进程。如果是RAC还会出现cross instance的CI调用相关的wait event.
分析与常见原因
- 检查DBWR进程cpu使用率
- 可以做CKPT进程的跟踪 或查看进程trace
- 分析可做HANGANALYZE 和 SYSTEMSTATEDUMP
CKPT进程会长时间持有 RO 排队,并使用 waitevent “enq: RO – fast object reuse” 阻塞其他操作。迄今为止报告受到影响的操作有:
– 在备用数据库中应用进程
– 收集统计数据
– truncate/drop
– 删除/缩小/更改表空间
TanelPoder在他的BLOG上What is the purpose of segment level checkpoint before DROP/TRUNCATE of a table?记录过,为什么在drop或truncate 前需要做segment level checkpoint , 简而言之就是防止已删除segment’s dirty buffers in buffer cache 后期部分被其实新segment reuse如direct path write to disk,DBWR在做flush dirty block 从buffer cache覆盖了disk上的原本属于新segment的block, 如果在dbwr进程写dirty block时再判断disk上的block的object是否已删除,需要调用数据据字典而变的复杂,DBWR 是一个低级别的后台进程为了提升效率它不该关心block的object,所以要在前期实现。
如果存在该性能问题时,首先排除是否有频繁的TRUNCATE /DROP ,尤其是较大的对象,这属于是业务逻辑问题,应该减少不必要的truncate,比如使用global temp table 解决。
truncate/drop 前应该了解的内容
truncate是DDL 删除表中所有记录降低HWM,重建segment,所以比DDL快生成的日志更少,可以在表级或分区级操作, 在做truncate时有几个事需要关注:
*使用shared pool中的相关sql cursor失效,再次hard parse
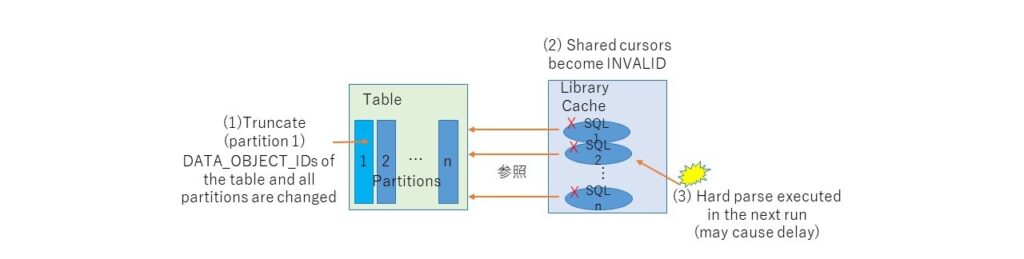
*Table 级锁定,即使是truncate partition
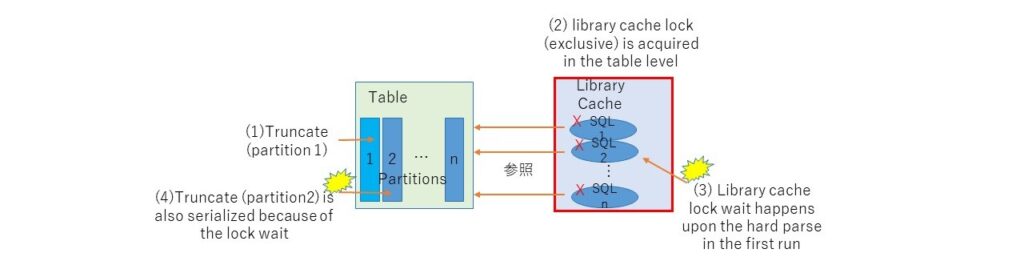
truncate 不仅会使相关 SQL 失效,还会以独占模式获得对表(不是分区)的“library cache lock”。此时,所有需要硬解析的 SQL 都将被阻止,因为它们也会尝试使用共享模式获取“library cache lock”。还值得注意的是,如果您尝试同时截断不同的分区,它将始终被序列化。
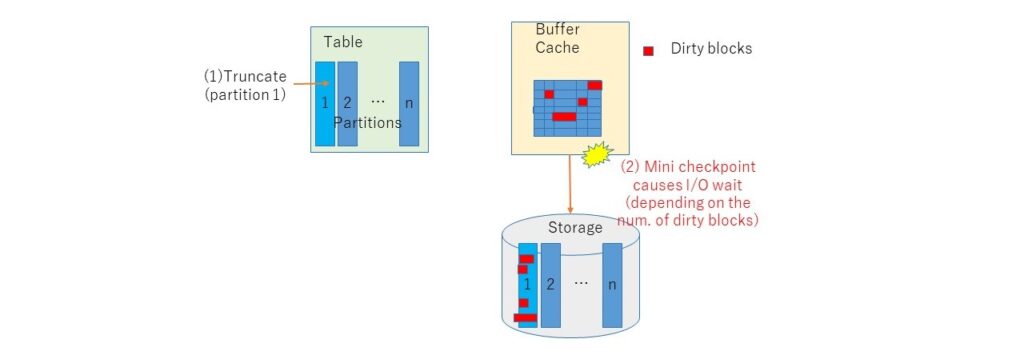
 * Object Checkpoint检查点
* Object Checkpoint检查点
上面有提到truncate要做checkpoint,有叫segment checkpoint有叫object checkpoint 还有叫做Mini-checkpoint, 将与truncate对象相关的缓冲区缓存中脏块刷新到其存储中。当脏块数量较大时,截断可能需要很长时间。此行为将被视为等待事件”enq: RO – fast object reuse”。
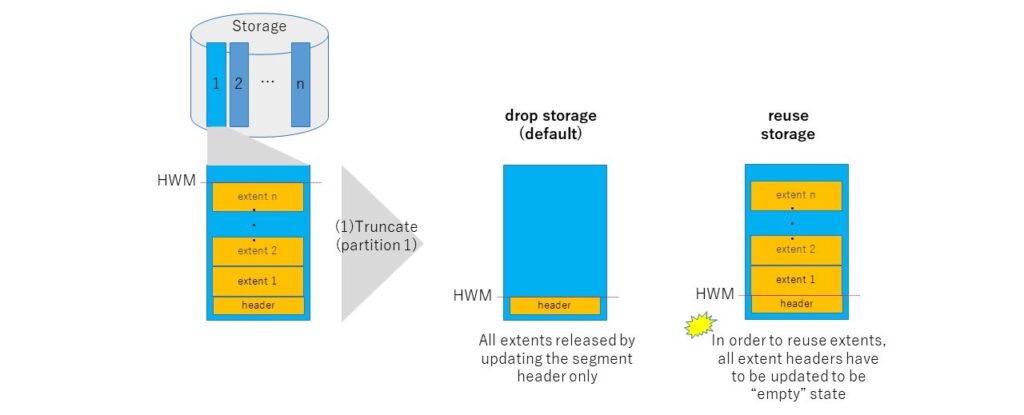
*truncate reuse storage可能更慢
truncate table xxx [reuse storage], 当使用reused storage 选项时,截断需要将所有盘区标记为空闲,并且需要时间,具体取决于段大小。
*update global indexes需要更多的时间
当使用分区表,truncate partition时,global index会不可用invalid, alter table xxx truncate partition xxx update global indexes, 它在内部是一个FULL TABLE SCAN,可能需要很长时间才能完成。建议使用partiton local index.
*I/O增加,DBWn CPU high
因为truncate前需要刷dirty block到存储,所以当大表时可能出现I/O增长,DBWR可能会使用大量的CPU,并且由于对象重用队列或检查点队列上有大量的空闲缓冲区,它的堆栈似乎在kcbo_write_q等模块中或周围旋转。在某些情况下,CKPT进程长时间保持RO队列,用等待事件“”阻塞其他操作。
Known BUGS
在oracle 11g前有些bug需要关注:
Bug 8544896 – Waits for “enq: RO – fast object reuse” with high DBWR CPU
Bug 7385253 – Slow Truncate / DBWR uses high CPU / CKPT blocks on RO enqueue
在11.2.0.3, 11.2.0.4 and 12.1.0.1的bug
Bug 18251841 TRUNCATE PARTITIONED TABLE SLOWER IN 11G THAN ON 10G
通常还伴随另一个wait event “enq: RO – fast object reuse”
“enq: RO – fast object reuse”
The RO enqueue known as “Multiple object resue” enqueue, is used to synchronise operations between foreground process and a background process such as DBWR or CKPT. It is typically used when dropping objects or truncating tables.
Following is the sequence of events When a truncate/drop occurs:
- Foreground process acquires the “RO” enqueue in exclusive mode
- Cross instance calls (or one call if it is a single object) are issued (“CI” enqueue is acquired)
- CKPT processes on each of instances requests the DBWR to write the dirty buffers to the disk and invalidate all the clean buffers.
- After DBWR completes writing all blocks, the foreground process releases the RO enqueue.
Known ISSUE
Bug 21422580 DBWR Using 100% CPU With ENQ: RO – FAST OBJECT REUSE During Truncate Or Drop Table –fixed 12.2 12.1.0.2.170418 11.2.0.4.180116
如果升级到oracle 19c(19.10及以后)上面这waite event比较突出,存在一个已知bug,
BUG 32117253 – TST&PERF:EBS: HIGH ENQ: RO – FAST OBJECT REUSE WAITS & ACTIVE CHECKPOINT QUEUE LATCH GETS
除了上属问题如果buffer cache较大时也可能加剧该问题,等待的时间还受扫描缓冲区缓存以查找要写入磁盘并从缓存中刷新的脏块所花费的时间的影响。buffer cache越大,找到这些块所需的时间就越长。如果缓冲区缓存非常大,则减小其大小对提高性能很有效。
还有可能存在较大的并行会话,在进行并行 DML 时,Oracle 使用直接路径读取来读取数据。为了确保正在读取的数据是一致的,尽管它需要检查将要读取的块。 CR enqueue 似乎用于将 CKPT 与读取数据的 PX slaves同步。它是这样的: PX slave 请求 CKPT 检查它即将读取的块范围(并且可能在 CR 上排队以便能够这样做) CKPT 依次命令 DBWR 写入请求范围内的所有脏块,等待此写入完成并向PX slaves发出块一致且可以读取的信号。由于最近在表上的 DML存在dirty block、因为大量的并行DML,导致繁忙的 CPU 和相对较慢的I/O写入,缓冲区缓存非常大并且其中很大一部分是脏的,当这些最近接触的表以直接路径模式读取时,此检查点可能会成为主要的性能抑制因素. 解决方法减少并行会话。
Bug 32117253 Performance optimization on global temporary table –fixed 19.12
Bug 28659098 Objects Compilation Is Taking Time Due To Drop Activity On Other PDB –fixed 20.1
Bug 8544896 Workaround:
1. Flush the buffer cache before truncating
2. Set _db_fast_obj_truncate = FALSE –这将恢复到使缓冲区缓存中的缓冲区失效的 9i 方式。
相关的DB 参数
SQL> @pd db_fast_obj
Show all parameters and session values from x$ksppi/x$ksppcv...
NUM N_HEX NAME VALUE DESCRIPTION
---------- ---------- -------------------------------------------------------- ------------------------------ ---------------------------------------------------------------------------------------------------
834 342 _db_fast_obj_truncate TRUE enable fast object truncate
835 343 _db_fast_obj_ckpt TRUE enable fast object checkpoint
914 392 _db_fast_obj_check FALSE enable fast object drop sanity check
Oracle 11g 中的一项新功能有关——快速对象检查点( fast object checkpointing)_db_fast_obj_ckpt=FALSE关闭了快速的对象检查点
分析SQL
SQL> select * from v$enqueue_statistics where eq_type in ('RO', 'KO');
EQ_NAME EQ REQ_REASON TOTAL_REQ# TOTAL_WAIT# SUCC_REQ# FAILED_REQ# CUM_WAIT_TIME REQ_DESCRIPTION
-------------------------- -- ---------------------- ---------- ----------- --------- ----------- ------------- ----------------------------------------
Multiple Object Reuse RO fast object reuse 1,039 82 1,038 0 1,040,219 Coordinates fast object reuse
Multiple Object Reuse RO contention 0 0 0 0 0 Coordinates flushing of multiple objects
Multiple Object Checkpoint KO fast object checkpoint 60 6 60 0 870,104 Coordinates fast object checkpoint
Reuse Block Range CR block range reuse ckpt 1,848 15 1,848 0 20 Coordinates fast block range reuse ckpt
SQL> select c.chain_id, c.chain_signature, c.sid, c.blocker_sid bsid, final_blocking_session final_bsid, s.program, s.sql_id, s.event
from v$wait_chains c, v$session s
where c.sid = s.sid order by c.chain_id, s.program;
CHAIN_ID CHAIN_SIGNATURE SID BSID FINAL_BSID PROGRAM SQL_ID EVENT
-------- ------------------------------------------------------- --- ---- ---------- ----------- ------------- -------------------------------
1 'rdbms ipc message'<='enq: KO - fast object checkpoint' 361 (CKPT) rdbms ipc message
1 'rdbms ipc message'<='enq: KO - fast object checkpoint' 543 361 361 sqlplus.exe 4wwzmhypuvnc6 enq: KO - fast object checkpoint
select * from V$ENQUEUE_STATISTICS
where (
lower(req_description) like '%checkpo%' or lower(req_description) like '%ckpt%'
or lower(req_description) like '%fast%reuse%'
or eq_type in ('CF', 'CR', 'KO', 'RO', 'TC', 'RT', 'HW')
)
and total_req# > 0;
可能的解决方案
SQL> ALTER SYSTEM SET "_db_fast_obj_truncate" = false sid = '*'; System altered. SQL> ALTER SYSTEM SET "_db_fast_obj_ckpt" = false sid = '*'; System altered.
select sql wait ‘library cache lock’ hold ‘CKPT’
因为中上面看到truncate 会使相关SQL失效,同时还会持有library cache lock的排他模式锁,如果此时执行select还可能出现library cache lock等待,’library cache lock’ Waits: Causes and Solutions (Doc ID 1952395.1) 有记录常见原因
1, 没有使用绑定变量
2,SQL ageout 因为shared pool不足或ASMM AMM动态调整
3,library cache object 无效,因为做了DDL如DROP/TRUNCATE 或统计信息收集
4, 对象多sessionn并发编译
5,audit on
6, 特性ACS, ECS, CURSOR_SHARING
7, row level trigger
etc..
Truncate – Causes Invalidations in the LIBRARY CACHE (Doc ID 123214.1)有记录相关样例
另外还有比较少见的2种场景:
1, 表空间free空间不足,需要回收recyclebin中的空间,此时AWR Top SQL中可能会出现”delete from RecycleBin$ where bo=:1″ 可以及时扩容表空间或手动一次性清理回收站中的历史droped对象
2, undo不足, 从系统性能中可以看到较大的undo偷窃现象, 观察v$undostat.UNXPSTEALCNT EXPSTEALCNT
可以查找大事务或临时扩容UNDO
建议
避免在在线交易频繁访问表的工作时间执行truncate, 不要并发大量的执行truncate table,
Reference
https://tech-oracle.blog.ss-blog.jp/2019-03-29