一套Oracle RAC环境经常的重启,日志中出现IPC time out 、LMSn has not moved for NN sec, 检查网络状态存在reassembly failures和RX-ERR和TX-ERR. 重组包的内核参数已经增加过,未解决问题,调整ring buffer后情况有所改善。
为了更好地分析网络瓶颈和性能问题,需要了解数据包如何接收。 数据包接收在网络性能调整中很重要,因为接收路径是帧经常丢失的地方。 接收路径中丢失帧可能会严重影响网络性能。
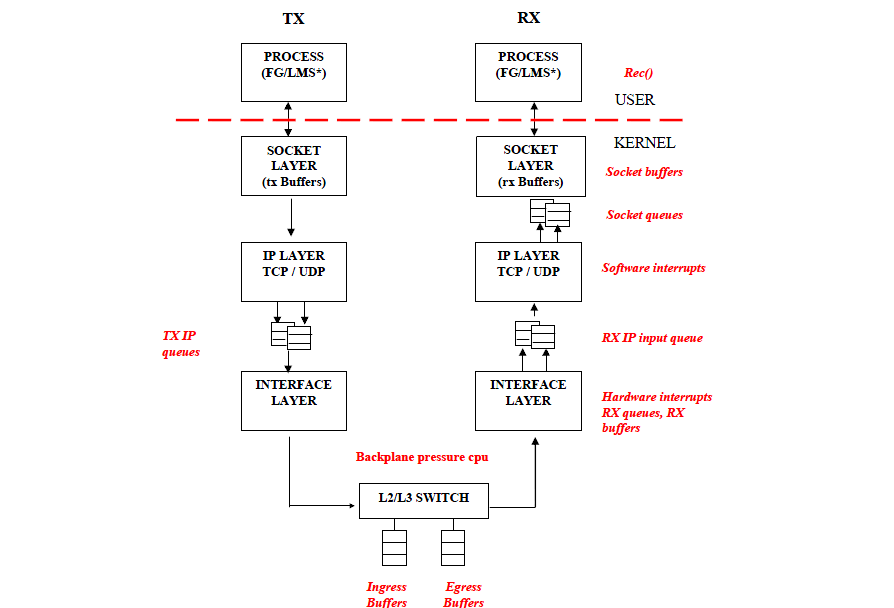
Linux内核接收每个帧并将其分为四个步骤:
1.硬件接收:网络接口卡(NIC)接收电线上的框架。 NIC根据其驱动程序配置,将帧传输到内部硬件buffer memory或指定的ring buffer。
2.HARD IRQ: NIC通过中断CPU来宣称网络帧的存在, 这使NIC驱动程序确认中断并安排软IRQ操作。
3.SOFT IRQ: 此阶段实现实际的帧接收过程,并在softirq上下文中运行。 这意味着该阶段会抢占在指定CPU上运行的所有应用程序,但仍允许宣称Hard IRQ。在这种情况下(与硬IRQ在同一CPU上运行,从而最大程度地减少了锁定开销),内核实际上从NIC硬件缓冲区中删除了帧,并通过网络堆栈。 从那里开始,将帧转发,丢弃或传递到目标侦听套接字。当传递给套接字时,框架将附加到拥有套接字的应用程序中。 反复进行此过程,直到NIC硬件缓冲区的帧用完为止。
4.Application receive: 应用程序接收帧并通过标准POSIX调用(read,recv,recvfrom)从任何拥有的套接字中使它dequeues。 此时,通过网络接收的数据不再存在于网络堆栈中。
到目前为止,丢帧的最常见原因是队列超限。 内核为队列的长度设置了限制,在某些情况下,队列填充的速度快于其耗尽的速度。 如果发生时间太长,帧开始dropped.。如上图所示,接收中有两个主要队列路径:NIC hardware buffer和socket queue.
NIC Hardware Buffer
检查方法使用
ethtool -S <NIC>
可以增加队列长度。 这涉及将指定队列中的缓冲区数量增加到驱动程序允许的最大数量。 使用ethtool修改rx,tx 的ring buffer. 调整ring buffer 是动态的不需要重启。但是不是持久性的,重启后会丢失配置,永久性修改 /etc/sysconfig/network-scripts/ifcfg-eth[x] 增加
ETHTOOL_OPTS=”-G rx 512″
或参考https://access.redhat.com/solutions/2127401
检查 # ethtool -g eth3 Ring parameters for eth3: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 256 RX Mini: 0 RX Jumbo: 0 TX: 256 Set rx/tx ring parameters of eth3: # ethtool -G eth3 rx 4096 tx 4096 Check settings of eth3 afterwards: # ethtool -g eth3 Ring parameters for eth3: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096
Socket Queue
检查方法使用 netstat 工具,the Recv-Q 列显示队列长度.
You can also avoid socket queue overruns by increasing the queue depth. To do so, increase the value of either the rmem_default kernel parameter or the SO_RCVBUF socket option.
如果udp的参数设置不合理,可能会产生“socket buffer overflows”,如果这个值非0, 需要增加udp_recvspace
-- AIX -- #no –a udp_recvspace udp_sendspace -- LINUX -- net.core.rmem_default = 4194304 net.core.rmem_max = 4194304 net.core.wmem_default = 4194304 net.core.wmem_max = 4194304 -- HPUX -- $ /bin/ndd -get /dev/sockets socket_udp_rcvbuf_default $ /bin/ndd -get /dev/sockets socket_udp_sndbuf_default -- Sun OS -- ndd -set /dev/udp udp_xmit_hiwat ndd -set /dev/udp udp_recv_hiwat ndd -set /dev/udp udp_max_buf <1M or higher>
_default值确定套接字创建后立即为每个套接字消耗多少内存。 _max值确定如果内存需求超出默认值,则允许每个套接字动态消耗多少内存。 因此,最佳实践建议是定义较低的默认值(即256k),以便在可能的情况下节省内存,但如果给定套接字需要更多的内存,则应具有较大的最大值(1MB或更大)以提高网络性能。每个OS的参数值可能不同,建议找OS厂家确认。
more : Intermittent Slower Network and Connection Timeouts (Doc ID 1614134.1)
Flow Control
检查方法
[root]# ethtool -a eth4 Pause parameters for eth4: Autonegotiate: on RX: on TX: on RX negotiated: off TX negotiated: off
如果接受端的流量远大于发送端的流量或者接受端的处理能力远小于发送端,那么这个时候就需要用到流量控制。流量控制分为发送端流量控制(用 tx 来表示)以及接受端流量控制(用 rx 来表示),在RHEL3\4中不建议启用流量控制,在新版的LINUX中默认是是启用的,流量控制简单理解为接受设备在处理不过来时回头一个”转停”帧,让发送端临时停止发送。
Troubleshooting gc block lost and Poor Network Performance in a RAC Environment (Doc ID 563566.1)
Flow-control mismatch in the interconnect communication path
Description: Flow control is the situation when a server may be transmitting data faster than a network peer (or network device in the path) can accept it. The receiving device may send a PAUSE frame requesting the sender to temporarily stop transmitting.
Action: Flow-control mismatches between switches and NICs on Servers, can result in lost packets and severe interconnect network performance degradation. In most cases the default setting of “ON” will yield best results, e.g:tx flow control should be turned on
rx flow control should be turned on
tx/rx flow control should be turned on for the switch(es)However, in some specific cases (e.g. Note 400959.1), such as bugs in OS drivers or switch firmware, a setting of OFF (on all network path) will yield better results.
NOTE: Flow control definitions may change after firmware/network driver upgrades. NIC & Switch settings should be verified after any upgrade. Use default settings unless hardware vendor suggests otherwise.
Oracle RAC 环境中block lost建议
如果RAC 出现较高的gc block corrupt可能是网络硬件问题。
如果是出现较高的gc cr/current block lost检查:
- UDP checksum错误
- Dropped packets/fragments
- Buffer overflows
- Packet reassembly failures or timeouts
- Ethernet Flow control kicks in
- TX/RX errors
排查方法
1,前提是检查CPU 负载是否过忙(>80% busy),或内存紧张现象;
2,检查LMS 进程是否是提升的优先级;
3,调整gcs_server_processes参数,增加更多的LMS进程;
4,网络调整:
4.1 先调重组内核参数,e.g.
net.ipv4.ipfrag_high_thresh = 16M --default 4M
net.ipv4.ipfrag_low_thresh = 15M -- default 3M
4.2 观察,再调 ring buffer, e.g
#!/bin/bash
if [ "$1" == "bond0" ]; then
/sbin/ethtool -G eth0 rx 4096 tx 4096
/sbin/ethtool -G eth1 rx 4096 tx 4096
fi
4.3 可以尝试启动流量控制. e.g.
Oracle recommeds that for the flow control Rx=on tx=off
/sbin/ethtool -A eth0 autoneg on tx off rx on
另外要注意查看CRS中的private interconnects中不要使用 oifcfg iflist 这个命令显示的可能是不正确的,可以忽略,这个命令更像是ifconfig,而不是真正ORACLE RAC使用的网络,而应该使用oifcfg getif替代。
注意事项:
常用命令 netstat
# netstat -in|while read LINE
do
echo $LINE| awk ' $1 !~ /\:/ {printf "%-15s %-15s %-15s %-15s %-15s %-15s %-15s %-15s \n",$1,$2,$5,$6,$7,$9,$10,$11}'
done
Kernel Interface
Iface MTU RX-ERR RX-DRP RX-OVR TX-ERR TX-DRP TX-OVR
bond0 1500 0 7930666 0 0 0 0
bond1 1500 1 2130865851 0 0 0 0
bond2 1500 0 972577 0 0 1 0
bond3 1500 15228 40009376 0 0 0 0
eth0 1500 0 1 0 0 0 0
eth1 1500 0 7924526 0 0 0 0
eth2 1500 1 1919295192 0 0 0 0
eth3 1500 7637 1256 0 0 0 0
eth4 1500 0 185341952 0 0 0 0
eth5 1500 7591 22992821 0 0 0 0
ib0 1500 0 943340 0 0 0 0
ib1 1500 0 29145 0 0 1 0
lo 16436 0 0 0 0 0 0
RX-ERR - Damaged/buggy packets recieved.
TX-ERR - Damaged/buggy packets sent.
Note:
The RX and TX columns show how many packets have been received or transmitted error-free (RX-OK/TX-OK) or damaged (RX-ERR/TX-ERR) how many were dropped (RX-DRP/TX-DRP); and how many were lost because of an overrun (RX-OVR/TX-OVR).
1, How to reset these counters?
The simplest way to clear these counter is to reboot. After system reboot all network interface counters will get refreshed. In order to do this without rebooting the system, follow below steps.
Find what particular ‘ethX’ network interface is using by. Look at the driver
ethtool -i eth0
Unload that driver from the kernel and then load it back again. This will clear the eth0 network interface counters.
modprobe -r ; modprobe ; ifup eth0
NOTE : These steps will bring down the network interface
oracle@kdhd1:/home/oracle>/sbin/ethtool -i eth3 driver: ixgbe version: 3.11.33-k firmware-version: 0x800003df bus-info: 0000:02:00.1 supports-statistics: yes supports-test: yes supports-eeprom-access: yes supports-register-dump: yes
2, if high count of RX-DRP. Red Hat Enterprise Linux 5.4
# ifconfig
RX packets:1130850672 errors:0 dropped:58292301 overruns:0 frame:0
# ethtool -S enp0s3|awk -F: ‘ $2>0 {print}’
rx_missed_errors: rx_missed_errors occur when you run out of fifo on the adapter itself, indicating the bus can’t be attained for long enough to keep the data rate up.
Resolution:
Update kernel
Update system BIOS and NIC firmware
Alter offloading settings
Get a more powerful NIC, or load balance the traffic in some way
you should increase ring buffer
# cat /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: ens1f0 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Slave Interface: ens1f0 MII Status: up Speed: 10000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: ac:f9:70:a9:a6:c4 Slave queue ID: 0 Slave Interface: ens2f0 MII Status: up Speed: 10000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: ac:f9:70:a9:a6:c2 Slave queue ID: 0 # /sbin/ethtool -g eth3 Ring parameters for eth3: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 512 RX Mini: 0 RX Jumbo: 0 TX: 512 #!/bin/bash if [ "$1" == "bond0" ]; then /sbin/ethtool -G eth0 rx 4096 tx 4096 /sbin/ethtool -G eth1 rx 4096 tx 4096 fi
3, rx_errors increasing on Mellanox ConnectX mlx4 Infiniband network interface
rx_errors indicates issues outside the operating system, either on the NIC or elsewhere within the network.
Resolution
Check for any updates to the device firmware.
Check for any updates to the kernel package, we recommend updating to the latest kernel if possible.
Try to increase the receive ring buffer: System dropping packets due to rx_fw_discards
stats->rx_errors = be64_to_cpu(mlx4_en_stats->PCS) + be32_to_cpu(mlx4_en_stats->RdropLength) + be32_to_cpu(mlx4_en_stats->RJBBR) + be32_to_cpu(mlx4_en_stats->RCRC) + be32_to_cpu(mlx4_en_stats->RRUNT); /* Drop due to overflow */ __be32 RdropLength; /* Received frames with a length greater than MTU octets and a bad CRC */ __be32 RJBBR; /* Received frames with a bad CRC that are not runts, jabbers, or alignment errors */ __be32 RCRC; /* Received frames with SFD with a length of less than 64 octets and a bad CRC */ __be32 RRUNT;
Root Cause
Counters like “discard” or “drop” in the output of ethtool -S ethX are caused by the exhaustion of the receive ring buffer.
Each packet received by the NIC is stored in the ring buffer while an interrupt is sent to the kernel to fetch the packet into kernel memory.
If the available buffer is filling up faster than the kernel can take the packets, there will be discarded packets.
Diagnostic Steps
Verify packet loss with: [root@host]# ip -s -s link Verify discards/drops/etc with: [root@host]# ethtool -S ethX Verify RX ring buffer current and maximum settings with: [root@host]# ethtool -g ethX
4, RHEL 7中统计到的package loss增加是因为RHEL 7中把之前版本中没有考虑的情况有增加
RHEL 7 differentiates packet loss from older o/s (RHEL 6 and RHEL 5), as rx drop counter can increment from the following reasons:
unrecognised protocol
unknown VLAN
unregistered multicast address.
Incremented for certain packets received by an inactive bond or team member.