前一篇写了《谈谈openClaw》,其实除了openClaw,对于初学者来说还有像agent, skill,MCP, Planning Code等名词,或很多人其实只知道名字,但不知道它们在 AI 技术体系里的位置。今天帮大家把这些概念全部讲清楚,并且告诉你它们之间的关系。
一、AI 技术栈
如果把 AI 应用看成一个完整系统,大致可以分成 5 层结构:
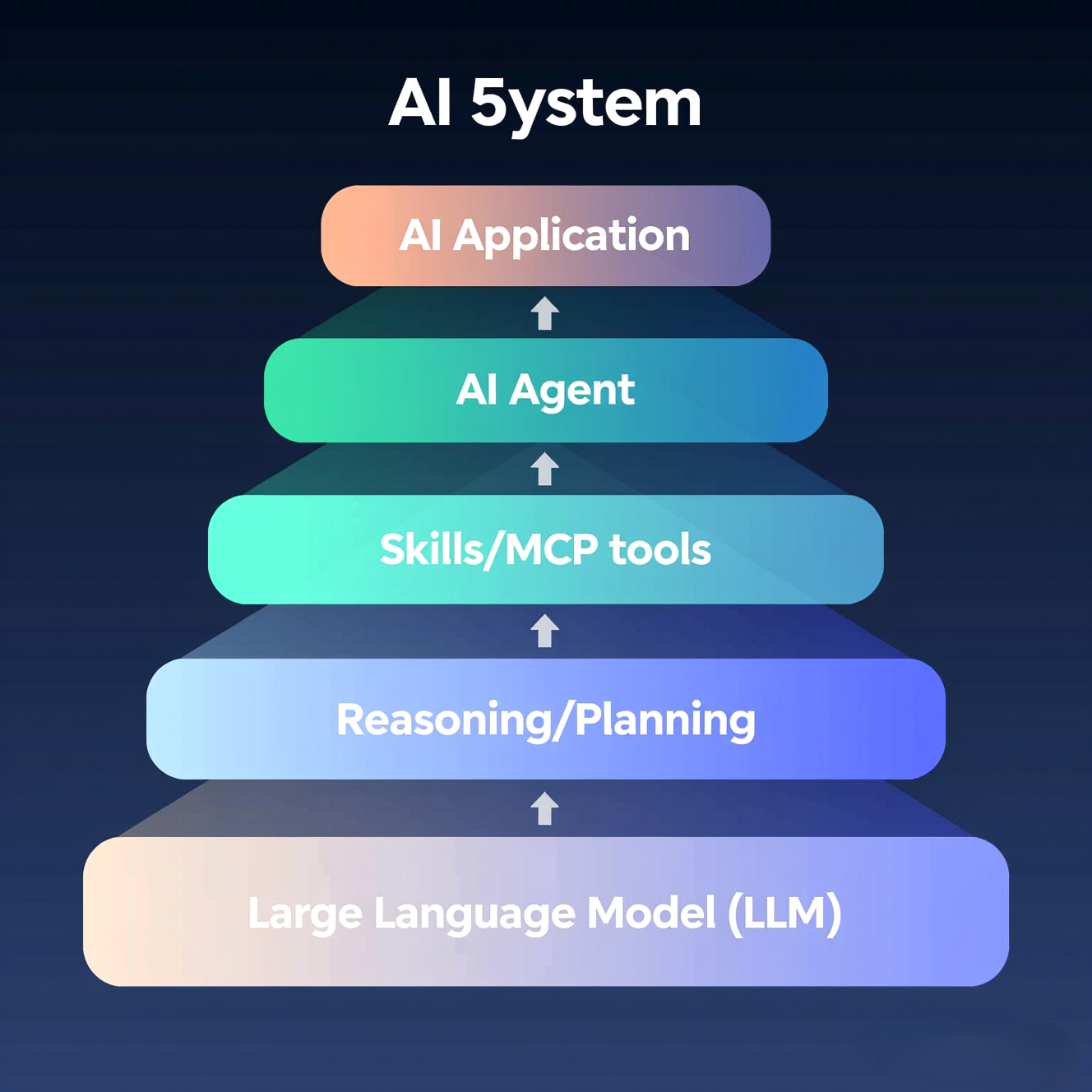
AI 应用架构示例, 如用户说:
帮我分析这个 GitHub 项目
AI 系统执行流程:
LLM 理解任务
↓
Planning 拆解任务
↓
Agent 执行任务
↓
MCP 访问 GitHub
↓
Skill 读取代码
↓
生成报告
二、大模型(LLM)
LLM(Large Language Model) 是整个 AI 体系的核心。
常见的大模型包括:
| 模型 | 公司 |
|---|---|
| GPT 系列 | OpenAI |
| Claude | Anthropic |
| Gemini | |
| Llama | Meta |
| Qwen | 阿里 |
| DeepSeek | 深度求索 |
| Abab/Speech | MiniMax |
| Kimi | 月之暗面 |
| GLM | 智谱 |
| Hunyuan | 腾讯 |
| Doubao | 字节跳动 |
| 文心 | 百度 |
这些模型主要能力:
- 自然语言理解
- 写代码
- 逻辑推理
- 知识问答
- 多模态(图像 / 视频 / 语音)
三、AI Agent(智能体)
AI Agent 可以理解为:一个可以自己思考、调用工具、执行任务的 AI 程序。
Agent 的本质就是:LLM + Planning + Tools
当前主流 AI Agent 可以分为三类:
| 类型 | 代表 |
|---|---|
| Agent框架 | LangChain、AutoGen、CrewAI、openClaw、LlamaIndex、阿里云百炼 |
| 自动Agent | AutoGPT、BabyAGI、MetaGPT、Qianwen-agent |
| 产品化Agent | Devin、OpenAI Assistants、Project Astra、Kimi Agent Builder、腾讯元宝 |
四、Planning(规划能力)
Planning 就是AI 在执行任务前,先把复杂问题拆成多个步骤。
Planning 就是:
AI 在执行任务前,先把复杂问题拆成多个步骤。
例如用户任务:
帮我开发一个 Todo App
AI 需要先规划:
1 设计数据库
2 写后端 API
3 写前端页面
4 集成测试
5 部署
这种能力就叫:
Task Planning
有些系统会用:
- Tree of Thought
- ReAct
- Plan & Execute
来实现。
五、Code Agent / Planning Code(规划型代码)
Planning Code 是一种比较新的 AI 编程模式,AI 先生成执行计划,再一步步写代码并执行。
Planning Code:
用户需求
↓
AI生成计划
↓
AI逐步写代码
↓
执行
↓
修复错误
↓
继续
这类系统通常叫:Code Agent
典型项目:
- OpenDevin
- Devin
- SWE-agent
- Claude Code
六、Claude Code
Claude Code 是 Anthropic 推出的 AI 编程代理工具。
它的特点是:
- 直接在终端运行
- 能理解整个代码仓库
- 自动写代码、修改代码、运行测试
核心能力:
读取代码
修改文件
运行命令
提交修改
例如你可以说:
修复这个项目里的单元测试错误
Claude Code 会:
- 扫描代码库
- 找到测试
- 运行测试
- 修改代码
- 再次运行
七、Agent Skill(技能)
在 Agent 系统中,Skill = AI 可以调用的能力模块
一个 Agent 可以有很多 Skill:
| Skill | 功能 |
|---|---|
| Search | 搜索互联网 |
| Python | 执行 Python |
| Browser | 打开网页 |
| File | 读写文件 |
| Database | 查询数据库 |
| 发送邮件 |
八、MCP(Model Context Protocol)
MCP 的目标是让 AI 可以标准化地连接各种工具和数据源。可以理解为:AI 世界的 USB 接口。
AI 可以通过 MCP 连接:
- GitHub
- Notion
- Google Drive
- 数据库
- 本地文件
结构类似:
LLM
↓
MCP Client
↓
MCP Server
↓
各种工具
以前每个 AI 工具都要自己写插件。现在只要支持 MCP:所有 AI 都可以使用同一套工具。
目前支持 MCP 的生态:
- Claude
- Cursor
- 一些 Agent 框架
九、Token
Token 是模型处理文本时的最小单位。AI 读文字时,不是按“字”或“单词”,而是按 Token 来计算和理解, Token = 文本被模型拆分后的单位.
大模型本质是数学模型,它不能直接理解:
- 字符
- 单词
- 句子
必须先把文本转换成 数字序列。
流程大概是:
文字
↓
Token
↓
数字ID
↓
模型计算
例如:
Hello → token 15496
world → token 995
模型看到的是:
[15496, 995]
很多 AI 服务收费是 按 token 计算的。模型计算量基本和 token 数量成正比。
Token 和字数的关系
大致可以这样估算:
| 文本 | 约等于 Token |
|---|---|
| 1个英文单词 | 1 token |
| 1个中文汉字 | 1–2 token |
| 1000英文词 | ~750 token |
| 1000中文字符 | ~1000–2000 token |
十、现在有什么技术可以节约大模型的TOKEN
在使用大模型(LLM)时,Token 成本和上下文长度是两个核心问题。很多公司和开发者都会想办法 减少 Token 使用量,目前业界主要有 节约 Token 的技术方法。核心原则是只给模型最必要的信息,按从简单到高级给你讲清楚。
- Prompt 压缩(Prompt Compression): 减少原始prompt中的非关键字
- 上下文裁剪(Context Truncation):只保留最近的N条对话
- 对话摘要(Conversation Summarization):把上文的内容总结,发送摘要
- RAG 检索(只发送相关内容):不要把 所有知识发给模型,只发送 相关内容
- 结构化 Prompt(减少冗余文本): 生成如json等结构化数据
- 小模型预处理(Two-Stage Model) : 用户输入再小模型处理转大模型生成。
- Prompt模板复用: 对于反复使用的同一个prompt,可以在存模板,只传变量
- mbedding + 向量检索: 把文档转换成 向量,存入向量数据库, 查询时只检索相关内容,不发送全部
- 缓存(Prompt Cache):两次请求类似,直接返回缓存结果,不再调用模型。
现在有些公司开始研究 “Token-Free LLM”(无Token模型),这可能会彻底改变大模型架构。目前主流的大模型(如 ChatGPT、Claude、Gemini)仍然是 Token-based LLM,也就是依赖 token 进行训练和推理。
Token-Free LLM
传统 LLM 的流程是:
文本
↓
tokenization(分词)
↓
token序列
↓
模型计算
Token-Free LLM 的目标是:
文本
↓
直接处理字符 / 字节 / 概念
↓
模型计算
Transformer 架构依赖 token. Transformer 的训练方式就是:预测下一个 token. 真正的 Token-Free LLM 还没有进入主流商业产品。
十一、大语言模型、 多模态模型、物理模型、世界模型
可以把 大语言模型、 多模态模型、物理模型、世界模型 看成 AI能力逐层增强的四个阶段。它们的核心区别在于:模型理解世界的深度不同。
| 类型 | 核心能力 | 主要输入 | 是否理解现实世界 |
|---|---|---|---|
| 大语言模型 | 语言理解和生成 | 文本 | 很弱 |
| 多模态模型 | 同时理解文本、图像、音频等 | 文本+图像+音频等 | 有一点 |
| 物理模型 | 理解现实世界物理规律 | 视频/交互 | 中等 |
| 世界模型 | 在内部模拟世界并预测未来 | 多模态+时间序列 | 很强 |
AI发展的一个典型路线
语言模型
↓
多模态模型
↓
理解不同信息物理模型
↓
理解现实规律世界模型
↓
在脑中模拟世界
现在几乎所有 AI(包括 ChatGPT)本质还是:
大语言模型 + 多模态能力
十二、Transformer和State Space Model(状态空间模型)
Transformer 的核心瓶颈:Attention 复杂度,Transformer 的核心机制是 Self-Attention(自注意力)。
它的计算复杂度是:
O(n²)
意思是:
| token数量 | 计算量 |
|---|---|
| 1000 | 100万 |
| 10000 | 1亿 |
| 100000 | 100亿 |
也就是说:
输入越长,计算量是 平方增长。
SSM 的计算复杂度:
O(n)
也就是 线性增长。
举个简单对比:
| 序列长度 | Transformer | SSM |
|---|---|---|
| 1k | 1M计算 | 1k计算 |
| 10k | 100M | 10k |
| 100k | 10B | 100k |
所以在 超长序列任务里,SSM理论上更高效。Transformer 推理有个问题:生成一个 token 时需要重新计算 attention。
而 SSM 的结构更像 RNN:
一步一步更新状态
所以推理延迟更低, SSM更适合之前提到过 Token-Free LLM。未来可能的方向:混合架构 Transformer + SSM
短上下文 → Transformer
长上下文 → SSM十三、AI名词里,哪些是要用户付费,哪些是免费的
AI 圈很多名词其实不是产品本身,而是技术或框架。主要是三类:概念、商业产品、开源或免费工具。
一、需要付费的 AI 产品(商业服务)
- 大模型服务,这些模型基本都是 API 按量付费(如按token,调用次数、算力、保月等)
- AI编程工具,如cursor, claude code, VS 等的专业版
二、免费的
- Ai agent框架,如autoGPT 但调用模型收费
- AI coding agent, 如openClaw
- 概念如 或MCP协议
AI 现在的商业模式是:
框架基本免费
工具部分免费
核心模型收费
十四、planning code和 coding plan 区别
在 AI Agent / 编程助手领域,经常提planning,因为 AI Agent 编程正在从“直接写代码”变成“先规划再执行”。像Planning Code 和 Coding Plan 常常被混用,但严格来说它们是 两个不同层级的概念。
可以简单理解为:
Coding Plan = 计划文档
Planning Code = 实现计划的代码逻辑
两者最核心区别
| 项目 | Coding Plan | Planning Code |
|---|---|---|
| 性质 | 文档 / 计划 | 程序代码 |
| 作用 | 指导开发 | 执行任务规划 |
| 使用者 | 人类 / AI | AI Agent |
| 输出形式 | 文本 | 代码 |
在 AI Coding Agent 中的关系
在现代 AI 编程系统里通常是这样的流程:
用户需求
↓
生成 Coding Plan
↓
写 Planning Code
↓
执行任务
↓
生成代码
如百炼(Bailian)的 Coding Plan,本质上属于:“AI Agent 的规划层(Planning Layer)能力”。也就是说,它更接近 Coding Plan(开发计划)这一类.
十五、AI Coding/Coding Agent
AI Coding/Coding Agent 仅用于编程场景,并不适用于如整理电脑文件、多视频编辑,相关的产品有
| 产品 | 公司 |
|---|---|
| Qwen-Coder | 阿里 |
| DeepSeek-Coder | DeepSeek |
| CodeGeeX | 智谱AI |
| 腾讯AI代码助手 | 腾讯 |
| Trae AI | 字节 |
十六、openClaw和 dify, manus 有什么区别
Dify (Define Your AI)是一个 AI 应用开发平台(开源)。可以低代码或无代码的可视化界面,拖拽式快速配置工作流,同样支持openAI, claude, deepseek,ollama等大语言模型。支持云端和本地部署。
它解决的问题是:
如何快速搭建 AI Agent / AI应用
Dify 提供:
- Agent workflow
- RAG
- Prompt管理
- Tool调用
- API部署
Manus 是一种 AI Agent 产品,是由中国团队 http://Monica.im开发。Manus 的工作原理是基于底层 AI 大模型的能力基础,通过自主任务分解将复杂任务拆解为多个子任务,并动态调用不同的 Agent 或工具来执行每个子任务,最终完成整体任务。
它的目标是:
让 AI 自己完成任务
OpenClaw、Dify 和 Manus 代表了当前(2025-2026年)AI Agent(人工智能体)领域中三种截然不同的产品形态和发展路线。简单来说,它们的区别可以概括为:
- Manus:“成品数字员工”。面向终端用户,开箱即用,全自动执行复杂任务,闭源商业服务。(全自动执行)
- 优势:门槛极低,具备强大的自主任务规划和多代理协作能力(规划、执行、验证自动完成),能处理跨软件的复杂工作流。
- 劣势:黑盒运作,用户难以干预中间过程;数据在云端,隐私依赖厂商信誉;需付费订阅
- Dify:“Agent 开发工厂”。面向开发者和企业,提供构建自定义 AI 应用的工具和框架,开源/私有化部署,需要自行编排。(可视化编排)
- 优势:灵活性极高,可深度定制业务逻辑;支持多种模型接入;适合企业构建知识库客服、内部助手等特定场景应用。
- 劣势:有学习成本,用户需要懂得如何拆解任务和编排流程;它本身不直接“帮你干活”,而是帮你造一个“能干活的工具”。
- OpenClaw:“本地极客工具箱”。面向技术爱好者和开发者,完全开源、本地优先运行,强调隐私控制和深度定制,通过即时通讯软件交互。
- 优势:数据隐私最高(数据不出本地);可直接控制本地环境(如操作本地 Excel、浏览器);完全免费且开源可改;支持长期本地记忆。
- 劣势:部署难度大(需配置 Docker、API Key、环境依赖),目前国内已有一键安装的产品;稳定性依赖用户自己的维护能力;
技术架构与部署:
- 部署位置:
- Manus:云端(厂商服务器)。
- Dify:可云端 SaaS,也可私有化部署(企业自建)。
- OpenClaw:本地优先(个人电脑/私有服务器)。
- 记忆与上下文:
- Manus:依赖云端会话,受限于 Token 长度,跨会话长期记忆较弱。
- Dify:依靠知识库(RAG)和变量管理,需开发者设计记忆机制。
- OpenClaw:内置工程化的本地持久记忆系统,能长期记录用户偏好和历史任务,更像是一个住在你电脑里的“老员工”, 所以才叫“养龙虾”, 使用越久,它越是了解你的使用习惯。
该如何选择?
- 如果你想要一个现成的、能立刻帮你写报告、做图表、查资料的“数字员工”,且不在乎付费和数据在云端,选 Manus。
- 如果你是一家公司,或者你是开发者,想要构建一个符合特定业务流程的 AI 客服、内部知识库或专用助手,选 Dify。
- 如果你是技术极客,极度重视隐私,希望 AI 能直接操作你电脑里的文件,并且喜欢折腾开源代码、完全掌控数据主权,选 OpenClaw。
这三者并非完全的竞争关系,更多是处于 AI Agent 生态的不同层级:Dify 是造轮子的平台,Manus 是造好的豪车,而 OpenClaw 则是给赛车手提供的改装套件。
十七、RAG检索增强生成
大模型(例如 GPT‑4 或 DeepSeek)有一个天然问题:它们不知道你的私有数据。
这些数据 不会在模型训练里出现。如果直接问模型,模型可能会:
- 胡编
- 给错误答案
这就是所谓的 AI幻觉。
RAG 的思路非常简单:回答前先检索资料。流程如下:
用户问题
↓
向知识库检索
↓
找到相关文档
↓
把文档放进 Prompt
↓
大模型生成答案AI Agent 时代的 RAG,RAG 就是 知识获取能力。在 Agent 体系里,RAG通常扮演:Knowledge Skill。私有知识必须 RAG,减少 Token 成本,防止模型幻觉。
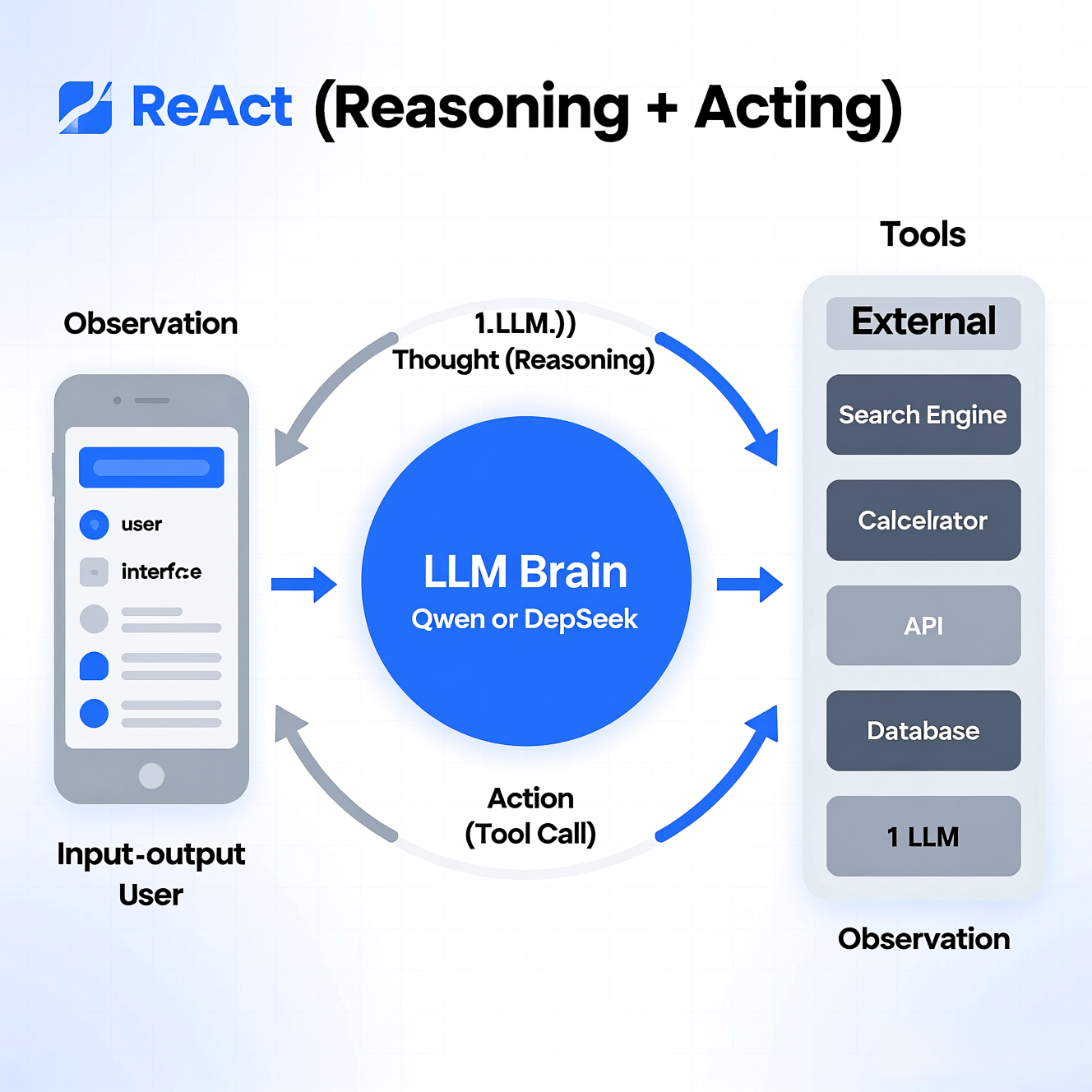
十八、React智能体
ReAct (Reasoning and Acting) 是由谷歌研究人员在 2022 年提出的一种范式。它的核心思想是:让大语言模型在执行任务时,交替进行“推理”(Thinking/Reasoning)和“行动”(Acting/Using Tools)。
传统的模型要么只思考(链式思维 CoT),要么直接调用工具。而 ReAct 智能体通过以下步骤循环工作:
- 观察 (Observation):接收用户输入或上一步工具返回的结果。
- 推理 (Thought):模型分析当前情况,决定下一步该做什么(例如:“我需要先搜索今天的天气”)。
- 行动 (Action):模型调用外部工具(如搜索引擎、计算器、数据库、API)。
- 重复:根据行动的结果再次推理,直到得出最终答案。
假设用户问:“2026年奥斯卡最佳影片是谁?请计算它的票房乘以10。”
一个基于 ReAct 范式 的智能体会这样工作:
- Thought: 我不知道2026年的奥斯卡结果,因为我训练数据没到那时候。我需要先搜索新闻。
- Action: 调用
Search_Tool(query="2026 奥斯卡最佳影片") - Observation: (搜索引擎返回) “2026年奥斯卡最佳影片是《未来纪元》”
- Thought: 现在我知道了电影名字,但我需要知道它的票房才能计算。
- Action: 调用
Search_Tool(query="电影《未来纪元》全球票房") - Observation: (搜索引擎返回) “票房为5亿美元”
- Thought: 现在我有数据了,5亿乘以10等于50亿。我可以回答用户了。
- Final Answer: 2026年奥斯卡最佳影片是《未来纪元》,其票房的10倍是50亿美元。
“国产 ReAct 智能体” 通常指的是支持 ReAct(推理+行动)范式的AI 智能体开发平台或大模型应用
— 持续更新…