oracle 11g R2环境1组normal冗余的ASM DISKGROUP包含3个cell的,每个cell为1个failgroup, 每个failgroup有48块ASM disks.因为一些硬件原因1个cell掉了19块disk,但offline后并未reblance完成,超过了“_asm_disk_repair_time”时间内没有online,被磁盘组自动drop force, 手动reblance时因为有1块asm disk使用不均衡free接近0MB,所以rebance会提示ora-15041错误。 此时add force与undrop均报错ora-15047. 处理rebalance需要空间,但加空间需要等上一个reblance完成的死结循环中。
如果此时改asm diskgroup的Power limit为0,并且配置15195 event ,leve 57,强制停止reblance再使用force add offline的disk加回原asm diskgroup时会提示ora-600[kfgcanRepartnero1][157][1][0]错误。如下
Total_MB Free_MB OS_MB Name
1906688 293860 0 _DROPPED_0001_CACHEDG
1906688 331408 0 _DROPPED_0002_CACHEDG
1906688 406388 0 _DROPPED_0011_CACHEDG
1906688 368836 0 _DROPPED_0012_CACHEDG
1906688 331412 0 _DROPPED_0013_CACHEDG
1906688 368904 0 _DROPPED_0018_CACHEDG
1906688 406440 0 _DROPPED_0019_CACHEDG
1906688 331404 0 _DROPPED_0021_CACHEDG
1906688 368952 0 _DROPPED_0023_CACHEDG
1906688 443916 0 _DROPPED_0025_CACHEDG
1906688 406416 0 _DROPPED_0031_CACHEDG
1906688 443964 0 _DROPPED_0032_CACHEDG
1906688 368844 0 _DROPPED_0033_CACHEDG
1906688 368928 0 _DROPPED_0034_CACHEDG
1906688 443952 0 _DROPPED_0035_CACHEDG
1906688 368908 0 _DROPPED_0036_CACHEDG
1906688 406424 0 _DROPPED_0037_CACHEDG
1906688 368872 0 _DROPPED_0038_CACHEDG
1906688 331380 0 _DROPPED_0039_CACHEDG
ORA-00600: internal error code, arguments: [kfgCanRepartner01], [157], [1], [0], [], [], [], [], [], [], [], []
ERROR: alter diskgroup cachedg add failgroup CELL01 disk '/dev/mapper/ANBOB_HDISK_CELL01_002' force,
'/dev/mapper/ANBOB_HDISK_CELL01_003' force,
'/dev/mapper/ANBOB_HDISK_CELL01_012' force,
'/dev/mapper/ANBOB_HDISK_CELL01_013' force,
'/dev/mapper/ANBOB_HDISK_CELL01_014' force,
'/dev/mapper/ANBOB_HDISK_CELL01_019' force,
'/dev/mapper/ANBOB_HDISK_CELL01_020' force,
'/dev/mapper/ANBOB_HDISK_CELL01_022' force,
'/dev/mapper/ANBOB_HDISK_CELL01_024' force,
'/dev/mapper/ANBOB_HDISK_CELL01_026' force,
'/dev/mapper/ANBOB_HDISK_CELL01_032' force
kfgpGet: insufficient space provided by caller. size 21, pcnt 20, KFPTNR_MAXTOT 20
因为多次反复的add disk,每次会增加不正确的记录到PST中,20个槽位已经耗尽,只要 diskpartner 总数为 低于 20 没有问题,但是一旦达到 20,重新平衡就需要完成才能执行和其他操作。
在之前分析故障ASM元数据丢失时提起过PST,PST全称Partner and Status Table,它记录了ASM中该磁盘组所有磁盘的磁盘号、磁盘之间的partner关系、failgroup信息、PST心跳信息以及磁盘状态,磁盘组冗余级别不同,PST的个数也不同,一般如下:
1.External Redundancy一般有一个PST
2.Normal Redundancy至多有个3个PST
3.High Redundancy至多有5个PST
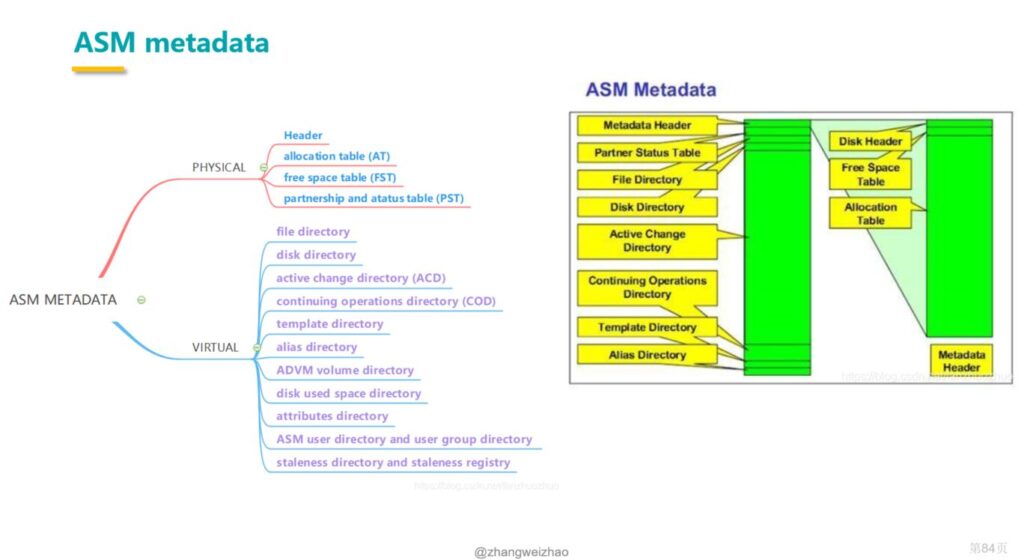 如果使用kfed读取disk header PST部分或查询x$kfdpartner查看每块磁盘的partner关系。如下
如果使用kfed读取disk header PST部分或查询x$kfdpartner查看每块磁盘的partner关系。如下
kfdpDtaEv1[1].partner[0]: 49152 ; 0x038: P=1 P=1 PART=0x0 kfdpDtaEv1[1].partner[1]: 49157 ; 0x03a: P=1 P=1 PART=0x5 kfdpDtaEv1[1].partner[2]: 49155 ; 0x03c: P=1 P=1 PART=0x3 kfdpDtaEv1[1].partner[3]: 49154 ; 0x03e: P=1 P=1 PART=0x2 kfdpDtaEv1[1].partner[4]: 10000 ; 0x040: P=0 P=0 PART=0x2710 kfdpDtaEv1[1].partner[5]: 0 ; 0x042: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[6]: 0 ; 0x044: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[7]: 0 ; 0x046: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[8]: 0 ; 0x048: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[9]: 0 ; 0x04a: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[10]: 0 ; 0x04c: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[11]: 0 ; 0x04e: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[12]: 0 ; 0x050: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[13]: 0 ; 0x052: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[14]: 0 ; 0x054: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[15]: 0 ; 0x056: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[16]: 0 ; 0x058: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[17]: 0 ; 0x05a: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[18]: 0 ; 0x05c: P=0 P=0 PART=0x0 kfdpDtaEv1[1].partner[19]: 0 ; 0x05e: P=0 P=0 PART=0x0
如你所见,PST 表限制了 20 个伙伴磁盘。partner[n]是partner slot,rebalance时就需要改动partner列表去实现,slot有三种状态:
active:(P=1 P=1)是有效的partner
drop:(P=0 P=1)是解除partner关系
new:(P=1 P=0)是新建立的partner关系
drop和new状态的slot会在rebalance操作完成之后被清理,从11g R2每块磁盘最多只能有8个active的partner slot,之前为10.
在删除并添加一些磁盘而没有重新平衡之后,我们有可能会出现超过 8个磁盘伙伴。
— 只有normal与high冗余才有partner.
查找ASM disk partner个数
SQL> select grp "Group#",disk "Disk#",NUMBER_KFDPARTNER "Partner
2 Disk#",PARITY_KFDPARTNER,ACTIVE_KFDPARTNER
3 from x$kfdpartner where GRP=2 ;
Group# Disk# Partner
Disk# PARITY_KFDPARTNER ACTIVE_KFDPARTNER
---------- ---------- ------------- ----------------- -----------------
2 0 110 1 0
2 0 126 1 0
2 0 66 1 0
2 0 100 1 0
2 0 53 1 0
2 0 99 1 0
2 0 81 1 1
2 0 87 1 0
2 0 73 1 0
2 0 96 1 0
..
-- add disk or drop disk without reblance completed
e.g.
select disk,count(NUMBER_KFDPARTNER), count(ACTIVE_KFDPARTNER)
from x$kfdpartner
where grp=1 group by disk;
比如DISK#与partner disk#为partner关系.这情况时就出现了ORA-15074。解决这个问题的唯一方法就是执行 rebalance。
分布
SQL> @pd asm_partner Show all parameters and session values from x$ksppi/x$ksppcv... NAME VALUE DESC ---------------------------------------- ---------- ------------------------------------------------------------------------------------------ _asm_partner_target_disk_part 8 target maximum number of disk partners for repartnering _asm_partner_target_fg_rel 4 target maximum number of failure group re
保证ASM DISKGROUP的分布与冗余度,同时重构PST需要遵循2个原则,由ASM隐藏参数控制:
1.每个failgroup只能最多与4个failgroup互为partner
2.每块磁盘只能最多与其他failgroup中的8块盘互为partner
如果是ASM自动触发的drop offline disk,等reblance完成,但reblance又报错无法完成
这个案例中发现有10块ASM disk达到20个。如果空间够,ASM diskgroup是11g compatibility可以指定: alter diskgroup xxx drop disk xxxxxxxx drop after 4H;删除后。可以增加_asm_repairquantum 让reblance完成后可增加新盘。如果REBLANCE完成后”_DROPPED*”的盘会自动v$asm_disk视图里清理掉,就可以add加盘。
模拟测试
SQL> alter diskgroup data drop disk DISK8 force rebalance power 0;
alter diskgroup data drop disk DISK8 force rebalance power 0
*
ERROR at line 1:
ORA-15032: not all alterations performed
ORA-15074: diskgroup DATA requires rebalance completion
SQL> alter diskgroup data rebalance power 10;
SQL> alter diskgroup data drop disk DISK8 force rebalance power 0;
Diskgroup altered.
SQL> alter diskgroup data add disk 'ORCL:DISK8' force rebalance power 0;
Diskgroup altered.
SQL> select disk,count(NUMBER_KFDPARTNER), count(ACTIVE_KFDPARTNER) from x$kfdpartner where grp=1 group by disk;
DISK COUNT(NUMBER_KFDPARTNER) COUNT(ACTIVE_KFDPARTNER)
---------- ------------------------ ------------------------
0 8 8
1 10 10
7 7 7
8 7 7
即使我们已删除并添加了相同的磁盘,PST 表也处于不平衡状态,我们需要尽快执行再平衡。
SQL> alter diskgroup data rebalance power 10;
Diskgroup altered.
SQL> select disk,count(NUMBER_KFDPARTNER), count(ACTIVE_KFDPARTNER) from x$kfdpartner where grp=1 group by disk;
DISK COUNT(NUMBER_KFDPARTNER) COUNT(ACTIVE_KFDPARTNER)
---------- ------------------------ ------------------------
0 8 8
1 8 8
8 8 8
9 7 7
但这个案例的问题是盘空间不足
1,是备份数据库重建ASM DISKGROUP还原
2,创建另一个am diskgroup迁移数据文件过去。
3, resize datafile。
ASMCMD> lsdsk -k -G xxx
观察经常有一块disk 的free MB为0,使用不均衡导致rebalance终止。 需要多次resize该ASM DISK相关的datafile和move 与这个ASM disk相关的datafile到其它组。