最近看到几个案例是国产MySQL系使用Thread Pool时出现的问题,有国内较主流的GoldenDB分布式数据库和电信自研TeleDB分布式数据库。现象是偶然的有些简单的SQL响应时间增加,只是因为在Thread pool阶段等待。
默认情况下,MySQL 使用“一连接一线程”的模型,即每个用户连接都会创建一个专用的操作系统线程来执行查询。然而,当连接数增加时,创建和管理大量线程会导致性能下降。线程池通过将用户连接与线程分离,优化了资源利用,提高了系统的性能和稳定性。但是MySQL社区版没有thread pool,Oracle把它增加到了企业版中,MariDB有提供,Percona移植了Maridb的threadpool并做优化,国产像Goldendb和Teledb for MySQL同样有Thread pool的功能。
线程池的工作原理
MySQL 线程池由多个线程组(Thread Group)组成,每个线程组管理一部分用户连接。每个线程组内有一个或多个线程负责执行用户查询。线程池通过限制每个线程组内的并发线程数,防止性能下降。
线程池的组成部分
- 队列:用于存放待执行的IO任务,分为高优先级队列和低优先级队列。高优先级队列的任务会优先处理。
- 监听线程:监听线程组的语句,并决定是立即执行还是放入队列。
- 工作线程:真正执行任务的线程。
- 定时器线程:周期性检查线程组是否阻塞,并通过唤醒或创建新线程来解决。
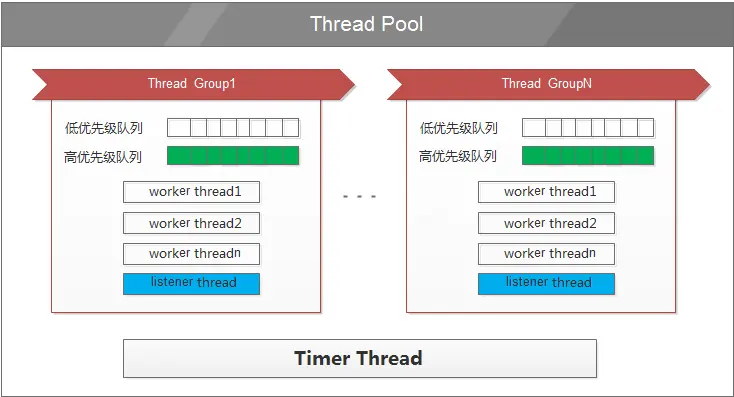
线程池会根据参数thread_pool_size的大小分成若干的group,每个group各自维护客户端发起的连接。当客户端发起连接到MySQL的时候,MySQL会跟进连接的线程id(thread_id)对thread_pool_size进行取模,分到对应的group。hread_pool_oversubscribe参数控制每个group的最大并发线程数,每个group的最大并发线程数为thread_pool_oversubscribe+1个,若对应的group达到了最大的并发线程数,则对应的连接就需要等待。
这个分配机制在某个group中有多个慢SQL的场景下会导致普通的SQL运行时间很长。这也是GoldenDB我们的实际场景中遇到最多的问题。
使用中的问题
- 内存泄漏:启用线程池后可能会出现内存泄漏问题,可以通过关闭 performance_schema 来解决。
- 拨测异常:当达到最大线程数时,新连接会卡在连接验证步骤,可以启用旁路管理端口来解决。
- 慢SQL问题:某些线程组内的慢SQL会导致新分配的线程等待,可以通过调整 thread_pool_oversubscribe 或优化慢SQL来解决。
案例1
环境TeleDB, 如果因为线程池内的分配线程时等待,前台等待的SQL慢不会进入MySQL slowSQL log. 如果查看session信息,有部分时间会话处于 login状态,user 显示为unauthenticated user
使用show variables like ‘thread%’,查看thread pool参数

疑点与thread_pool_oversubscribe有关,出问题的数据库上有多个 canal进行在进行数据同步,binlog dump进程也计算在内。
用AI可以几秒生成测试脚本,以下是一段用于测试 MySQL 数据库连接在多线程环境下性能的 Python 脚本。该脚本使用 concurrent.futures.ThreadPoolExecutor 创建多线程,并通过 pymysql 连接数据库。当连接耗时超过 1 秒时,会打印出具体的耗时时间,可用于诊断 thread_pool_oversubscribe 参数配置不当导致的线程饥饿或连接延迟问题。
import time
import logging
from concurrent.futures import ThreadPoolExecutor, as_completed
import pymysql
from pymysql.err import OperationalError
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(threadName)s] %(message)s'
)
logger = logging.getLogger(__name__)
# 数据库连接配置
DB_CONFIG = {
'host': '127.0.0.1',
'port': 3306,
'user': 'your_username',
'password': 'your_password',
'connect_timeout': 5 # 连接超时设置为5秒
}
# 连接测试函数
def test_connection(connection_id):
start_time = time.time()
conn = None
try:
conn = pymysql.connect(**DB_CONFIG)
end_time = time.time()
conn.close()
duration = end_time - start_time
if duration > 1.0:
logger.warning(f"连接 {connection_id} 耗时过长: {duration:.2f} 秒")
else:
logger.info(f"连接 {connection_id} 成功,耗时: {duration:.2f} 秒")
return duration
except OperationalError as e:
end_time = time.time()
duration = end_time - start_time
logger.error(f"连接 {connection_id} 失败,耗时 {duration:.2f} 秒: {e}")
return duration
except Exception as e:
end_time = time.time()
duration = end_time - start_time
logger.error(f"连接 {connection_id} 发生未知错误,耗时 {duration:.2f} 秒: {e}")
return duration
# 主函数
def main():
num_threads = 50 # 模拟50个并发连接
timeout_threshold = 1.0
print(f"启动 {num_threads} 个并发线程测试 MySQL 连接...")
print(f"警告:连接时间超过 {timeout_threshold} 秒将被记录。")
with ThreadPoolExecutor(max_workers=num_threads, thread_name_prefix="DBConn") as executor:
# 提交任务
futures = [executor.submit(test_connection, i) for i in range(num_threads)]
# 收集结果
durations = []
for future in as_completed(futures):
duration = future.result()
durations.append(duration)
# 输出统计信息
long_connections = [d for d in durations if d > 1.0]
print(f"\n测试完成。")
print(f"总连接数: {len(durations)}")
print(f"超过1秒的连接数: {len(long_connections)}")
if long_connections:
print(f"长连接耗时详情: {[f'{d:.2f}s' for d in sorted(long_connections, reverse=True)]}")
if __name__ == '__main__':
main()为了尽快显示问题,可以临时调小thread_pool_size, 执行脚本很快复现了该问题。
案例2
环境GoldenDB, 通过proxy可以查看到链路报错的thread_id号,根据thread_id找到出问题对应的慢查询日志。分析DN节点的慢查询日志,重点看req_wait_time, 线程池等待时间(ms), 如果该时间过长,大概率就是thread pool队列分配时发生了堵塞,也就是thread_pool_size*thread_pool_oversubscribe 大小偏小,调整该大小,当然值与CPU个数有关,不是盲目调大。当然更多见的是应用在某个时间段的一个大SQL或长事务,长时间占用线程池资源,如晚上跑批时告警较多,这时多是先kill 会话,给其他SQL放行,再优化SQL.
解决方法
thread_pool_oversubscribe 调整为16后,测试该问题已基本消失, 这同样也是我们一些GoldenDB生产环境的值,但是如果生产库有很多大事务,还是难免会出现简单SQL因为thead pool的分配等待而响应时间变长,此时可以继续尝试增加thread_pool_oversubscribe 到32. 当然最核心的是优化分配算法,如果连commit都要等待,那确实不合理。